







Fast csv writing for R
R has traditionally been very slow at reading and writing csv files of, say, 1 million rows or more. Getting data into R is often the first task a user needs to do and if they have a poor experience (either hard to use, or very slow) they are less likely to progress. The data.table package in R solved csv import convenience and speed in 2013 by implementing data.table::fread() in C. The examples at that time were 30 seconds down to 3 seconds to read 50MB and over 1 hour down to 8 minute to read 20GB. In 2015 Hadley Wickham implemented readr::read_csv() in C++.
But what about writing csv files?
It is often the case that the end goal of work in R is a report, a visualization or a summary of some form. Not anything large. So we don’t really need to export large data, right? It turns out that the combination of speed, expressiveness and advanced abilities of R (particularly data.table) mean that it can be faster (so I’m told) to export the data from other environments (e.g. a database), manipulate in R, and export back to the database, than it is keeping the data in the database. However, the data export step out of R being the biggest bottleneck preventing that workflow is being increasingly heard from practitioners in the field. The export step may be needed to send clean data or derived features to other teams or systems in the user’s organization.
Yes: feather , I hear you thinking! Indeed feather is a new fast uncompressed binary format which is also cross-language, by Wes McKinney and Hadley Wickham. As Roger Peng pointed out R has had fast XDR binary format for many years but the innovation of feather is that it is compatible with Python and Julia and other systems will adopt the format too. This is a great thing. Note that it is very important to set compress=FALSE in save() and saveRDS() to achieve comparable times to feather using base R.
I was thinking about jumping on board with feather when to my surprise 2 weeks ago, the data.table project received a new user contribution from Otto Seiskari: fwrite(). Analogous to fread() it writes a data.frame or data.table to .csv and is implemented in C. I looked at the source and realized a few speed improvements could be made. Over the years I’ve occasionally mulled over different approaches. This contribution gave me the nudge to give those ideas a try.
The first change I made was to stop using the fprintf() function in C. This takes a file handle and a format specification string and writes a field to the file. If you have 1 million rows and 6 columns that’s 6 million calls to that function. I’ve never looked at its source code but I guessed that because it was being iteratively called 6 million times, some tasks like interpreting the format specification string and checking the file handle is valid were being performed over and over again wastefully. I knew it maintains its own internal buffer automatically to save writing too many very small chunks of data to disk. But I wondered how much time was spent writing data to the disk versus how much time was spent formatting that data. So I added my own in-memory buffer, writing to it directly and moved from fprintf() to the lower level C functions write(). Note: not the C function fwrite() but write(). This writes a buffer of data to a file; it doesn’t have an internal buffer in the way. I did this so I could wrap the write() call with a timing block and see how much time was being spent writing to file versus formatting.
Here is the result :
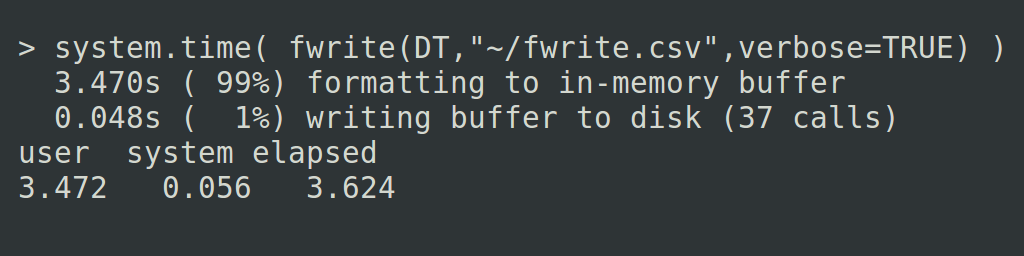
Wow: 99% of the time is being spent formatting! The time is not spent writing to disk at all. Not one ounce.
Can we parallelize it then? On first glance, the data has to be written to the file in a serial fashion: row 1, then row 2, then row 3. Perhaps the data could be divided into N subsets, each subset written out in parallel, then joined together afterwards. Before rushing ahead and doing it that way, let’s think what the problems might be. First the N subsets could be writing at the same time (to different files) but that could saturate the internal bus (I don’t know much about that). Once the N files are obtained, they still have to be joined together into one file. I searched online and asked my colleagues and it appears they is no way to create a file by reference to existing files; you have to concatenate the N files into a new single file (a copy). That step would be serial and would also churn through disk space. It’s possible there would not be enough disk space available to complete the task. Having anticipated these problems, is there a better way I could implement from the get go?
What did I have one of that I could make N of? Well, I had one buffer: the input to write(). If I make N threads and give each thread its own buffer can it be made to work? This is inherently thread safe since the only memory write would be to a thread’s private buffer. The only tricky aspect is ensuring that each piece is written to the output csv file in the correct order. I’m on good terms with Norman Matloff who has recommended OpenMP to me in the past and kindly gave me a copy of his excellent book Parallel Computing for Data Science .
I turned to Google and quickly found that OpenMP has exactly the construct I needed :
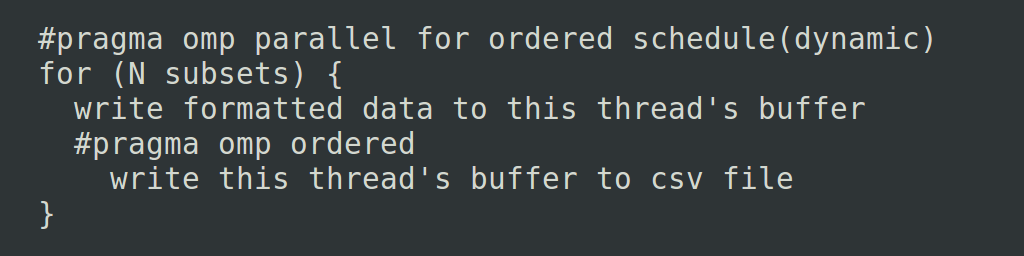
OpenMP does a lot of work for the programmer. It directs the team of threads to work on each iteration of the for loop. The code after the #pragma omp order gets executed one-at-a-time and in-the-order-of-the-for-loop, automatically. So if iteration 7 finishes quickly for some reason, that thread will wait for iterations 1-6 to finish before it writes its buffer and receives the next piece to work on.
I chose the buffer size for each thread to be small (1MB) to fit in each core’s cache. This results in the number of pieces N to be much larger (size of data / 1MB) than the number of threads so that each piece is not too big to get stuck and cause a blockage and not too small either to incur wasteful startup and scheduling overhead.
Here is the result on my 4-core MacBook Pro (running bare-metal Ubuntu, of course):
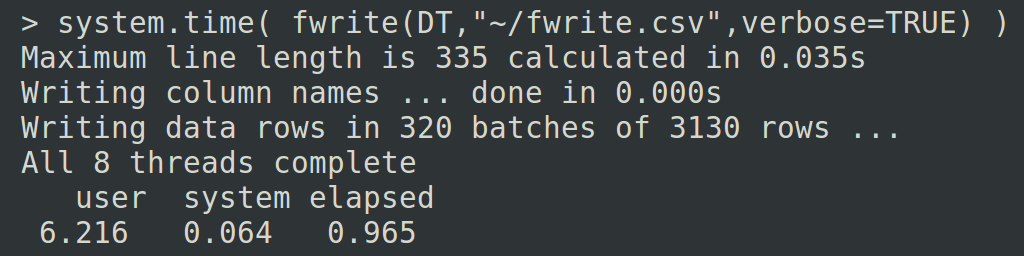
This was one of those rare moments where the speedup factor was the best I hoped for. An ideal 4x improvement: 3.6 seconds down to 0.9 seconds .
I thought I’d have to add lots of tests for fwrite() but I looked at the test suite and found that Otto had already added 26 tests in his pull request that I’d merged. My changes had broken quite a few of them so I fixed the code to pass his tests. Then I pushed to GitHub for others to test on MacOS and Windows. Within hours feedback came back that the speedup and correctness were confirmed.
One outstanding itch was that each field was being written to the buffer by the C function sprintf(). Although this is writing to an in-memory buffer directly, I wondered how big the overhead of interpreting the format string and actually calling the library function was. I knew from fread() that specialized code that is tuned to be iterated can make a big difference. So I created specialized writeNumeric and writeInteger functions in C using base R’s C source code (e.g. format.c:scientific() ) as a guide to give me some clues.
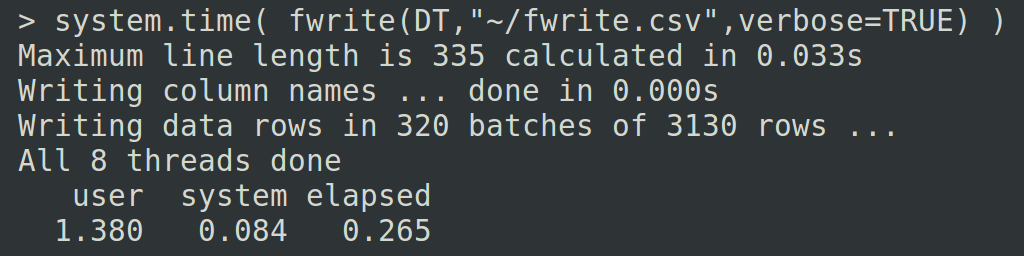
That’s better. Another 3x speedup: 0.9 seconds down to 0.3 . This feels like the lower bound to me. So far we’ve been working with 1 million rows and an output csv file of around 150MB. Quite small by many standards. Let’s scale up 10x to 10 million rows on my laptop with SSD and 100x to 100 million rows on one of our 32 core / 256 GB physical servers. The reproducible code is at the end of this article. On the server we test writing to ram disk (/run/shm) versus writing to hard disk. Ram disk may be appropriate for ephemeral needs;
e.g. transferring to a database where there is no requirement to keep the transfer file.
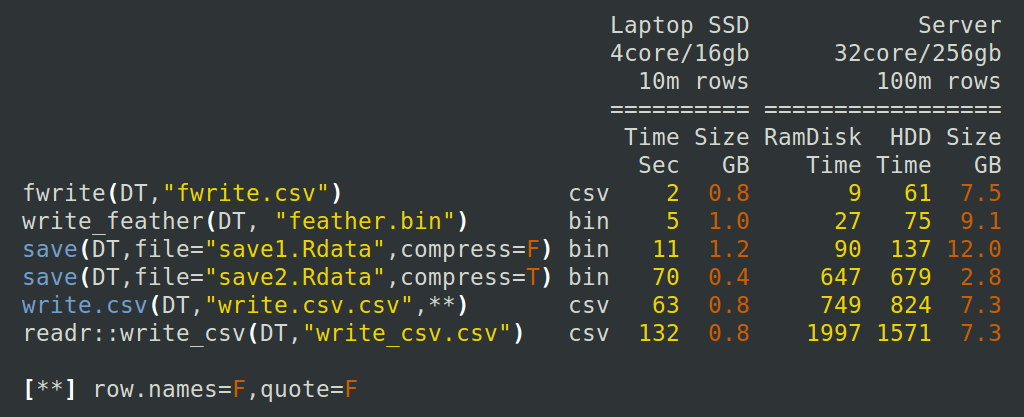
To my surprise, writing a csv file using data.table::fwrite() appears to be faster than writing a binary file with feather. Your mileage may of course vary. If you ever need to quickly inspect the data using familiar command line text tools like head, tail, wc, grep and sed then it seems that csv files are still in the running then. Sometimes a csv format can turn out to be quite efficient. Consider the number 1.2 for example. In R that is an 8 byte ‘double’ but in the csv it’s just 3 characters wide, a 62% saving. This may be why the csv size (7.5GB) is slightly smaller than the binary (9.1GB).
Here’s a small display of the data being tested:
fwrite is available to test now in data.table v1.9.7 in development. Check out our installation notes for how to install the dev version and get OpenMP where necessary. Please try it out and let us know your findings. It works just as well on both data.frame and data.table . Note there are some outstanding items to complete before release to CRAN, collated here .
fwrite() is a great improvement over write.csv(): 63 seconds down to 2 seconds for the 10 million row test on my laptop. write.csv() converts the input to character format first in-memory. This creates new string objects for each and every unique integer or numeric which takes compute cycles to create and hits the global character cache (a hash table) and uses more RAM. There is an advantage of doing it that way, though. The character conversion is object oriented so many user or package defined classes with their own print methods in R code will just work automatically with no C programming required.
What’s the connection to H2O?
Usually you would import data into H2O using h2o.importFile() called from either the R or Python H2O packages. h2o.importFile() has been parallel and distributed for some years. To test big-join I’m using it to load two 200GB files into a 10 node cluster with 2TB of RAM, for example. I’ll write more about this in a future article. Sometimes however, it’s necessary or convenient to transfer data between H2O and the R client. This step currently uses base R’s write.csv and read.csv. We intend to replace these calls with fwrite/fread. We’ll also look at the H2O Python package and see if we can improve that similarly.
If you’d like to hear more about big-join in H2O I’ll be presenting at our Open H2O Tour in Chicago on May 3rd , 2016 together with lots of other amazing people including Leland Wilkinson, Jeff Chapman, Erin LeDell, Mark Landry and others. And use the promo code H2OYEAH to get a 50% discount. Also please catch up with me at Data-by-the-Bay where I’ll be presenting on May 16th, 2016 .
This article was also published on R-Bloggers here: http://www.r-bloggers.com/fast-csv-writing-for-r/
Appendix
Reproducible code adapted from this Stack Overflow question
install.packages(“data.table”, type=”source”, repos=”https://Rdatatable.github.io/data.table”)
For Mac and Windows, see https://github.com/Rdatatable/data.table/wiki/Installation
require(data.table) # v1.9.7
devtools::install_github(“wesm/feather/R”)
require(feather) # v0.0.0.9000
require(readr) # CRAN v0.2.2
DTn = function(N) data.table( # or data.frame. Both work just as well.
str1=sample(sprintf(“%010d”,sample(N,1e5,replace=TRUE)), N, replace=TRUE),
str2=sample(sprintf(“%09d”,sample(N,1e5,replace=TRUE)), N, replace=TRUE),
str3=sample(sapply(sample(2:30, 100, TRUE), function(n) paste0(sample(LETTERS, n, TRUE), collapse=””)), N, TRUE),
str4=sprintf(“%05d”,sample(sample(1e5,50),N,TRUE)),
num1=sample(round(rnorm(1e6,mean=6.5,sd=15),2), N, replace=TRUE),
num2=sample(round(rnorm(1e6,mean=6.5,sd=15),10), N, replace=TRUE),
str5=sample(c(“Y”,”N”),N,TRUE),
str6=sample(c(“M”,”F”),N,TRUE),
int1=sample(ceiling(rexp(1e6)), N, replace=TRUE),
int2=sample(N,N,replace=TRUE)-N/2
)
set.seed(21)
DT = DTn(1e6)
Either ram disk :
setwd(“/dev/shm”)
or HDD/SDD :
setwd(“~”)
system.time(fwrite(DT,”fwrite.csv”))
system.time(write_feather(DT, “feather.bin”))
system.time(save(DT,file=”save1.Rdata”,compress=F))
system.time(save(DT,file=”save2.Rdata”,compress=T))
system.time(write.csv(DT,”write.csv.csv”,row.names=F,quote=F))
system.time(readr::write_csv(DT,”write_csv.csv”))
NB: It works just as well on both data.frame and data.table







