Meet Yauhen Babakhin: The first and the only Kaggle Grandmaster from Belarus
There is more to competitive Data Science than simply applying algorithms to get the best possible model. The main takeaway from participating in these competitions is that they provide an excellent opportunity for learning and skill-building. The learnings can then be utilized in one’s academic or professional life. Kaggle is one of the most well-known platforms for Data Science competitions , which offers a chance to compete on some of the most intriguing machine learning problems. People of myriad experiences take part in these competitions. Some people do extremely well and go on to achieve the title of Kaggle Grandmasters. In this series, I bring to light the amazing stories of Kaggle Grandmasters.
In this interview, I’ll be sharing my interaction with Yauhen Babakhin , a Kaggle Competitions Grandmaster, and a Data Scientist at H2O.a i. Yauhen holds a master’s degree in Applied Data Analysis and has more than five years of experience in the Data Science domain. Yauhen happens to be the first Kaggle competitions’ Grandmaster in Belarus, having secured gold medals in both classic Machine Learning and Deep Learning competitions.
Here is an excerpt from my conversation with Yauhen:
- You were the first Kaggle competitions Grandmaster in Belarus. What initially attracted you to Kaggle, and when did the first win come your way?
Yauhen: I started my journey in Data Science with an online course on Edx . There was a Kaggle competition as a part of the course, and it was for the first time that I was introduced to the concept of Kaggle. I managed the 450th position (with a top-50 position on the Public Leaderboard) in the competition, but it was a great learning lesson and motivation to continue learning Data Science. After about six months, I took part in my second Kaggle competition and won a silver medal there.
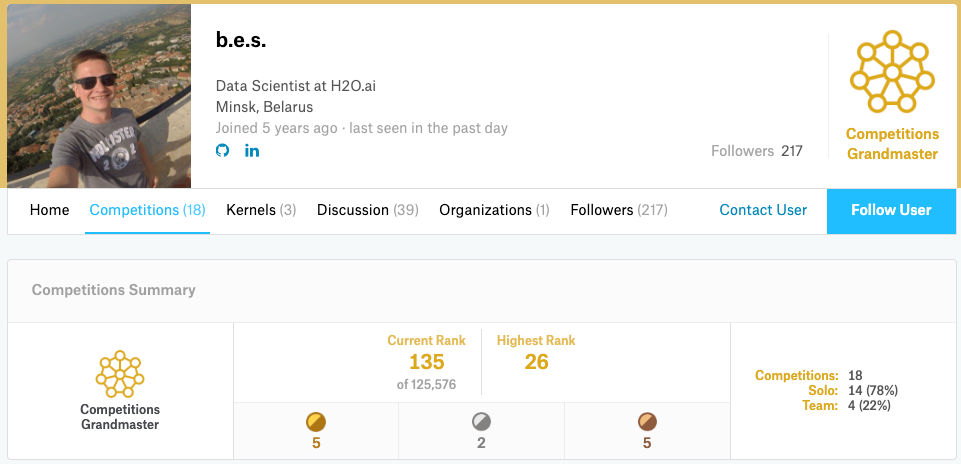
Currently, I’m the first and the only one Kaggle Grandmaster in Belarus, but there are a good number of Kaggle Masters, and the Data Science community is growing really fast.
- You have gold medals in both classic Machine Learning and Deep Learning competitions. Which competitions do you find more challenging?
Yauhen: I would say that all the competitions are challenging, but if I were to choose, I’d say it’s comparatively harder to participate in the Deep Learning competitions. Deep learning competitions entail long training times, so it isn’t possible to iterate fast. This makes it hard to evaluate all the hypotheses, and one has a much lower scope for making errors.
- How do you typically approach a Kaggle problem?
Yauhen: I usually wait for a week or two after the launch of a competition. If there are some problems with competition like data leaks, incorrect data, etc., these are located in the first few weeks, and a lot of time is saved.
Then, just like everyone else, I begin with the exploratory data analysis part followed by hypothesis generation, establishing local validation, and trying different ideas and approaches. Usually, I create a document where I store all these thoughts, assumptions, papers, and resources that, I think, could work for this particular competition. Sometimes such a document can even contain up to 20 pages of text.
In addition to the above methodologies, I make it a point to follow all the forums and kernels discussions during the competition to get different opinions on the same problem.
- What are your favorite resources when it comes to Data Science in general? Which programming languages do you prefer?
Yauhen: It’s hard to follow every resource possible as the progress in Machine Learning, and Data Science is happening at a very rapid pace. So, I try to limit myself to a specific domain or a specific problem that I’m working on at the moment.
First of all, I would name the Open Data Science community (ods.ai) . It’s mostly a Russian-speaking slack community with about 40 thousand members and channels on almost every topic in Data Science. One can quickly get information on any Data Science concept in a matter of seconds here. However, if I need a deeper understanding of any material, I go directly to some blog posts, papers, youtube videos, etc.
Speaking about the programming language, I started my journey in Data Science using the R language, but now I mostly use Python .
- As a Data Scientist here at H2O.ai, what are your roles and in which specific areas do you work?
Yauhen: I’m currently working on the AutoML models in the Computer Vision domain . H2O.ai’s Driverless AI is already equipped to work with tabular, time series, and text data. Now we’re moving forward to use Driverless AI with the images’ data for solving problems like classification , segmentation, object detection, etc
The idea is that once the user provides a CSV file with paths to the images and image labels, Driverless AI should automatically build the best model out of this data, given the time constraint. This would entail automating all the hyperparameters search such as the learning rate, optimizer, neural net architecture, etc. and the training process like the number of epochs, augmentations selection, etc. Moreover, this process should be efficient in terms of time and memory used. We are working on this and getting some positive results.
- What are some of the best things that you have learned via Kaggle that you apply in your professional work at H2O.ai?
Yauhen: I’ve participated in several Kaggle competitions with the images data. It gives a nice background knowing what ideas work best on practice and which of them could be automated. Also, I continue reading solutions of the competition winners, even if I didn’t take part in a particular competition.
Such practical tricks are not generally described in any book or online course. That’s why Kaggle allows one to stay on the edge of the field development and to improve our AutoML pipeline for the Computer Vision problems continuously.
Yauhen(3 from R) with other ‘Makers’ during the H2O Prague Meetup
- Are there any specific areas or problems where you would want to apply your expertise in ML?
Yauhen: I have substantial experience in a lot of domains, like classic Machine Learning, NLP, and Computer Vision. However, I have never worked with audio data. So, it would be interesting to apply some techniques for problems, as the classification of the audio recordings or natural language understanding, to name a few.
- A word of advice for the Data Science aspirants who have just started or wish to start their Data Science journey?
Yauhen: In my opinion, one should bear in mind that the Data Science journey should ideally be a combination of theoretical knowledge and practical experience.
Just reading the books, blog posts, skimming through online courses will not give you any hands-on experience. You will only obtain some theoretical understanding that you won’t be able to apply in practice. On the other hand, going right away to the application would also become a monkey job. Running simple fit()-predict() and blindly copying public Kaggle kernels, without any understanding of what’s going on under the hood, would also lead you nowhere.
So, I would suggest picking a good online course and completing all its exercises. Additionally, participate in Kaggle competitions and apply the theoretical methods that you’ve just learned from papers, books, blog posts, etc. In this way, you’ll have a firm grasp of the fundamentals and will understand their practical utilities also.
Yauhen(7 from L) with other H2O.ai Kaggle Grandmasters during H2O world New York
This interview is another great example to show how people like Yauhen work hard in a systematic manner to achieve their goals. They define a clear path and work towards their goal. Another great takeaway from this conversation is that having good theoretical knowledge is only useful to a certain extent. Still, the real test of your understanding is only when you put your learnings into practice.
Read other interviews in this series: