This blog was originally published on towardsdatascience: https://towardsdatascience.com/getting-started-with-h2o-using-flow-b560b5d969b8
A look into H2O’s open-source UI for combining code execution, text, plots, and rich media in a single document.
Data collection is easy. Decision making is hard.
Today, we have access to a humungous amount of data, which is only increasing day by day. This is primarily due to the surge in the data collection capabilities and the increased computing power to store this collected data. However, collecting data is one thing, and making sense of it is entirely another. Deriving insights from data should be fast and easy, and the results obtained should be interpreted and explained easily. H2O offers a single platform that makes both scoring and modeling, possible, through faster and better predictive modeling.
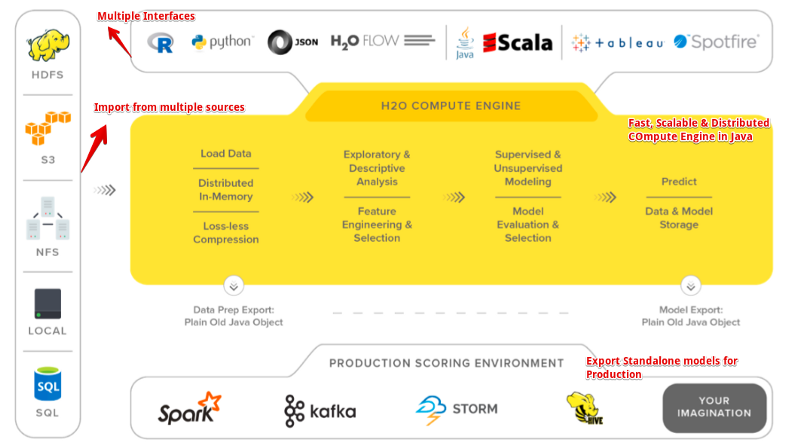
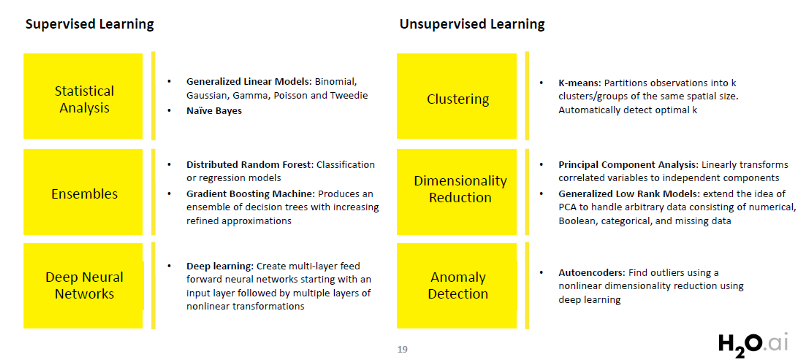
H2O is an in-memory platform for distributed and scalable machine learning. Incidentally, H2O is both the name of the product and that of the company(H2O.ai ) behind it. It is fully open-sourced and uses familiar interfaces like R, Python, Scala, Java, JSON, and even a web interface. The latest version of H2O is called H2O-3, and it works seamlessly with multiple big data technologies like Spark and Hadoop. Also, H2O supports a lot of commonly used algorithms of Machine Learning, such as GBM , Random Forest , Deep Neural Networks , Word2Vec , and Stacked Ensembles , to name a few.
H2O Flow
H2O Flow is a standalone interface to H2O. We can use our browser to point to localhost and then communicate directly with the H2O engine without having to deal with Python or R or any other another language. It’s a great tool to quickly model data using all the great algorithms available in H2O through a simple web interface without any programming. One can easily run a neural network, GBM, GLM, K-means, Naive Bayes, etc. with just a few clicks.
Flow is a web-based interface of H2O and a great way for new users to get started and learn all available features and algorithms that H2O has to offer.
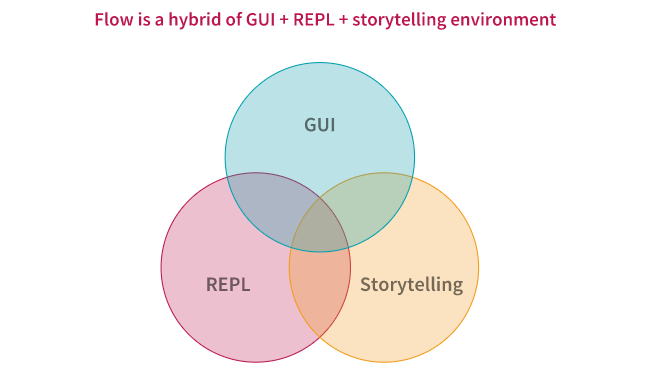
Flow can be thought of as a hybrid of GUI + REPL + storytelling environment for exploratory data analysis and machine learning, with async, re-scriptable record/replay capabilities. Here is an excellent user guide on H2O Flow for reading more about it.
Setup
H2O runs on Java which is a pre-requisite for it to work. H2O uses Java 7 or later, which you can get at the Java download page.
Download H2O from this link and follow the steps as defined below.
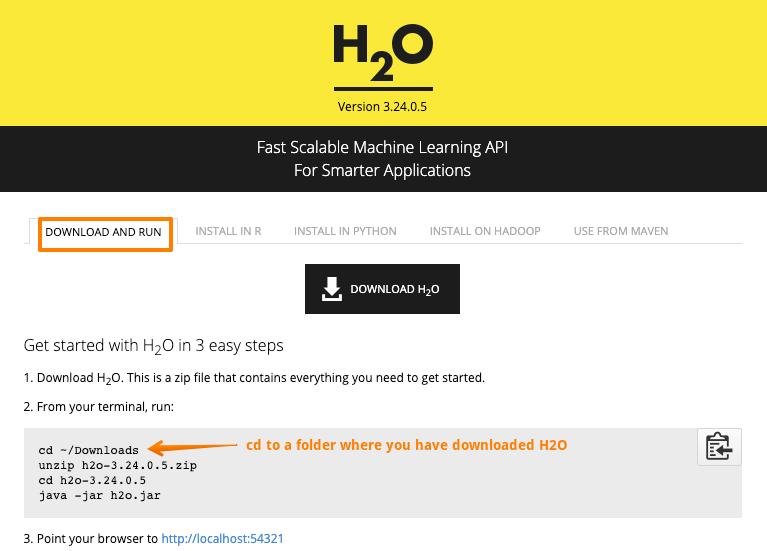
Once installed and running, point the browser to http://localhost:54321 to access the Flow interface.
Interface
If you have worked with Jupyter Notebook, the interface of Flow will appear very familiar to you. Just like in Jupyter Notebooks, Flow also has two cell modes: edit and command. Visit this link to understand more about Cell Modes.
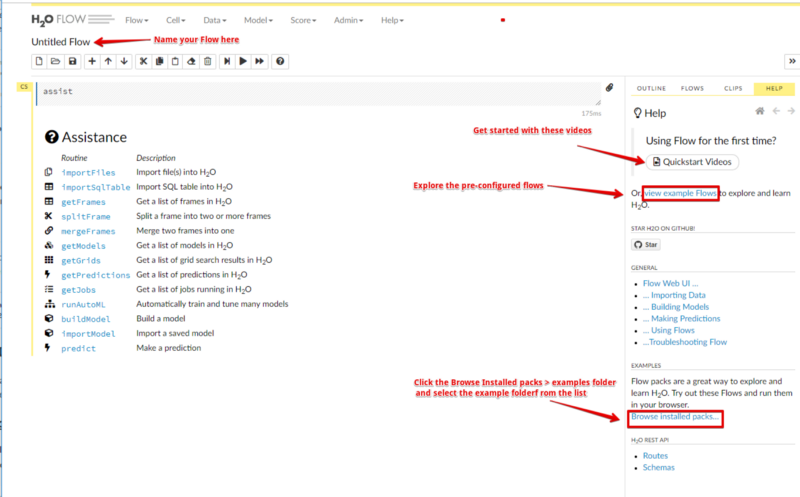
Flow Interface
Working
Flow sends commands to H2O as a sequence of executable cells. The cells can be modified, rearranged, or saved to a library. In Flow, we can alternate between text cells and executable cells where we can either type or have H2O generate a CoffeeScript that can be run programmatically and shared between users. To execute a cell, either hit CTRL+ENTER or use the Run icon in the toolbar.Let’s now use H2O in the Flow UI to work on a Machine Learning problem and look at its various features closely.
Predicting Customer churn using H2O
Predicting customer churn is a reasonably known problem in the space of Customer Relationship Management (CRM) and is a crucial element of modern marketing strategies. Retaining a customer is very important for organizations, and we shall see how H2O can play a vital role in the data science pipeline by rapidly creating predictive models and then using the insights to increase customer retention.
The dataset used belongs to the 2009 KDD Cup Challenge. This can also be accessed under the Examples > Browse installed packs > examples > KDDCup 2009_Churn.flowin the Flow interface. Alternatively, use the following links for accessing the training and validation data, respectively:
Here is the Flow pipeline that we will be using to perform the training and the predictions.

Machine Learning Pipeline
1. Importing /Uploading Data
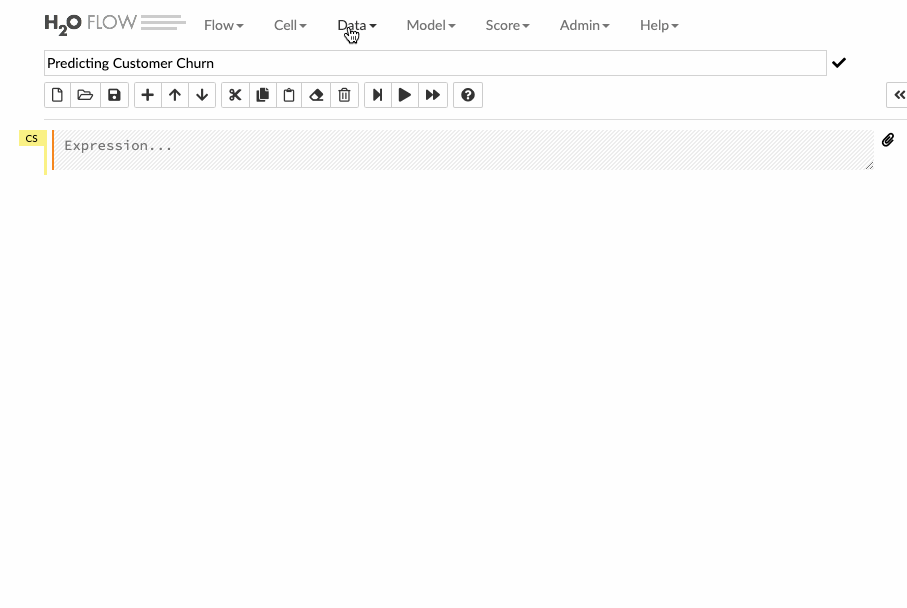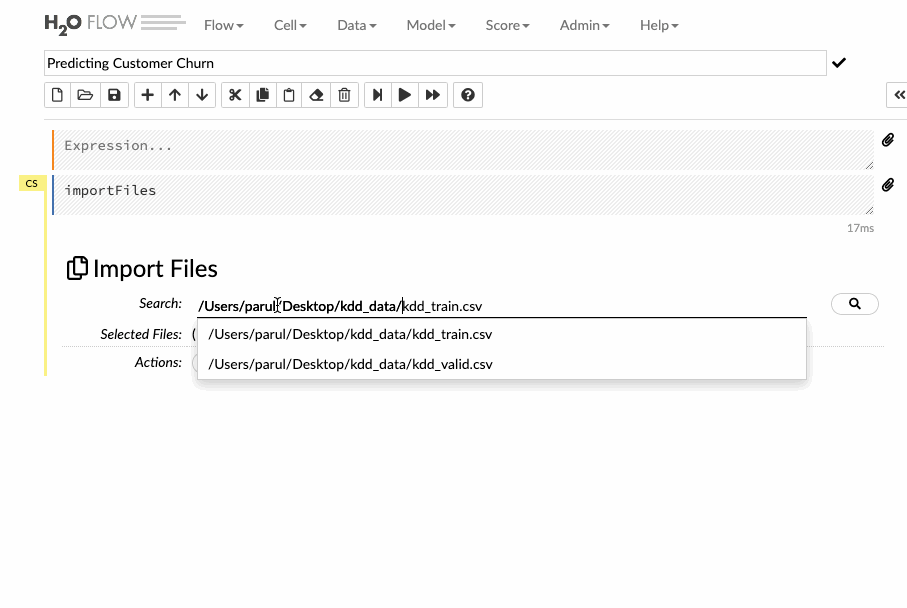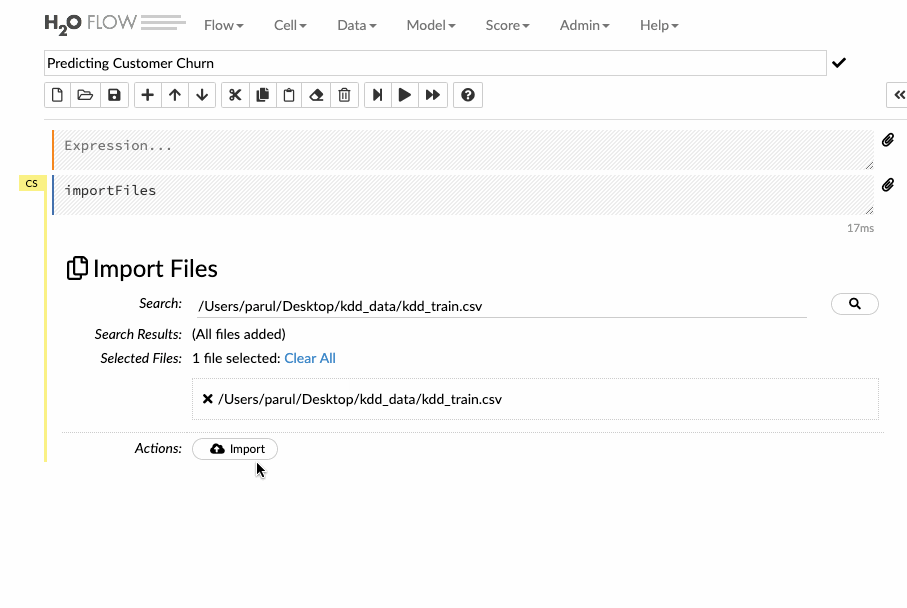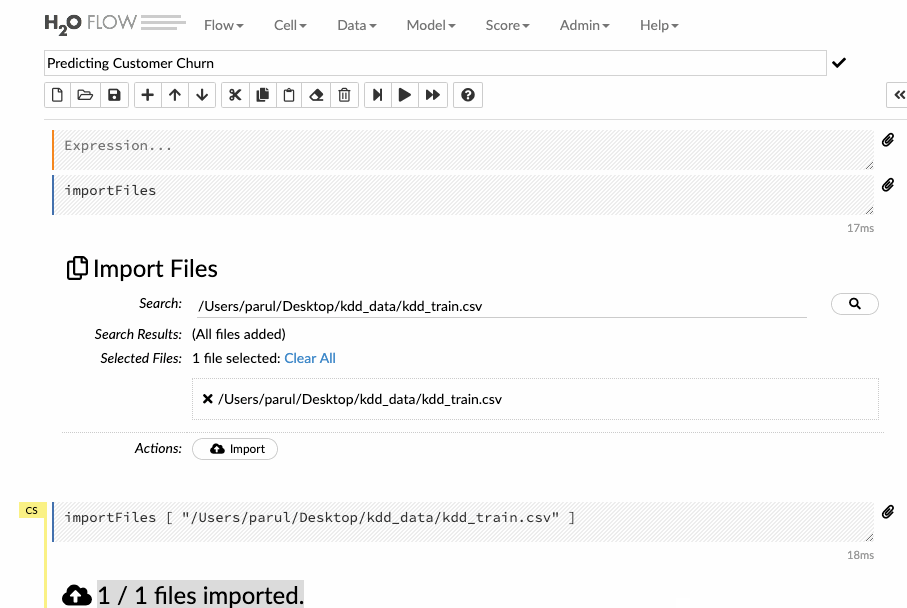
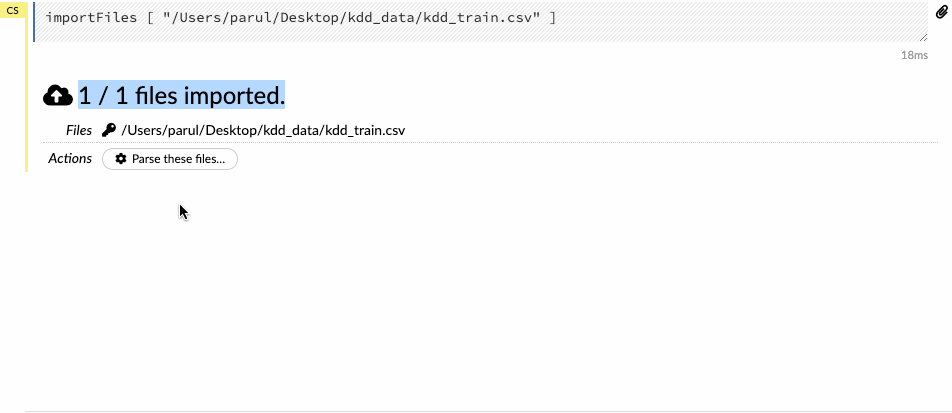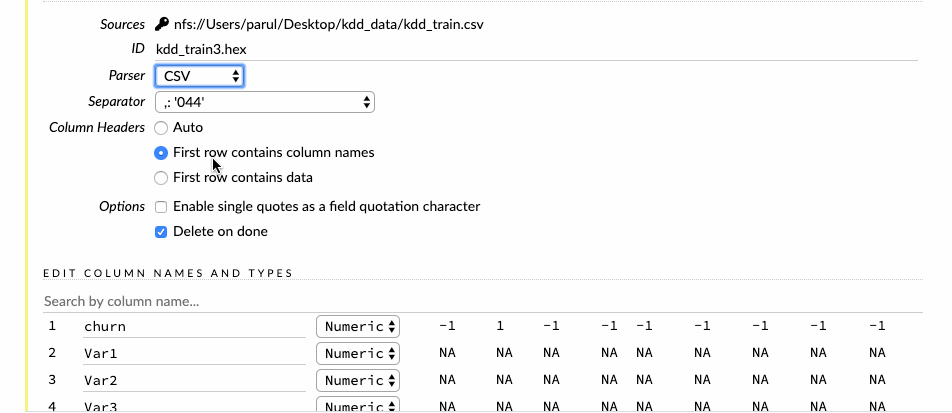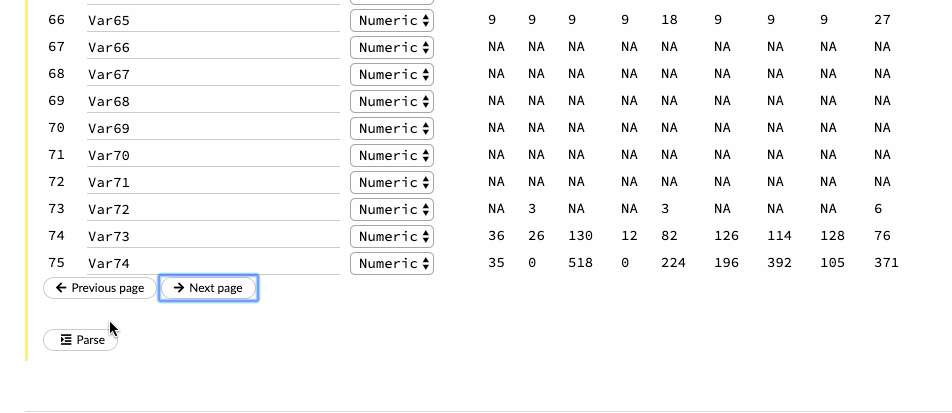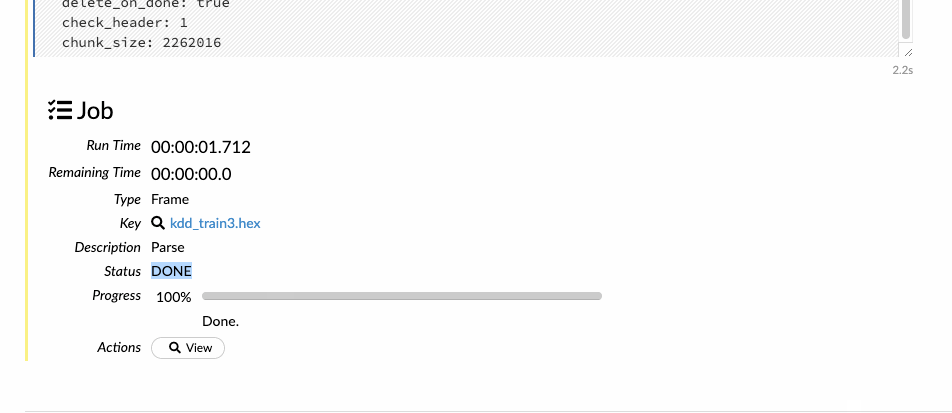
Enter the file path in the auto-completing Search entry field and press Enter. Select the file from the search results and confirm it by clicking the Add All link. We can also upload a local file or can directly mention the url of the dataset.
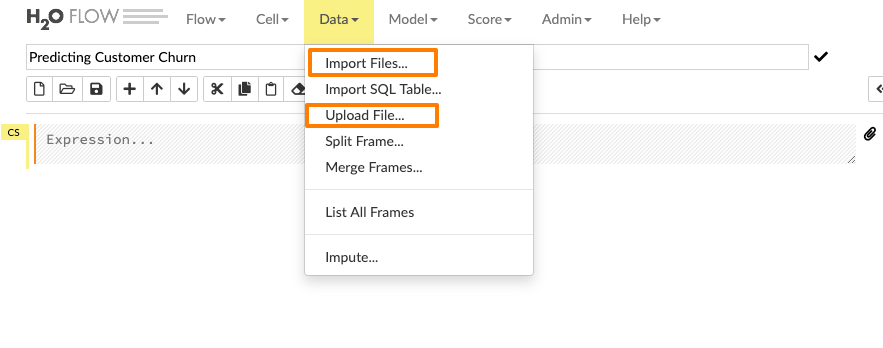
Let’s see how we can import the training data into the flow interface.
Parsing Data
The next step is to parse the imported data. We can select the type of parsers, but most of the times, H2O figures it out automatically for us. During the parse Setup page, we get to choose the column names as well as the column types. For the churn column, let’s change the datatype from numeric to enum, which stands for a categorical variable. Churn column is the response column so, during the model building process, this column will get automatically expanded into the dummy variables.
Next, when you hit the parse button, the data is parsed and converted to a .hex format.
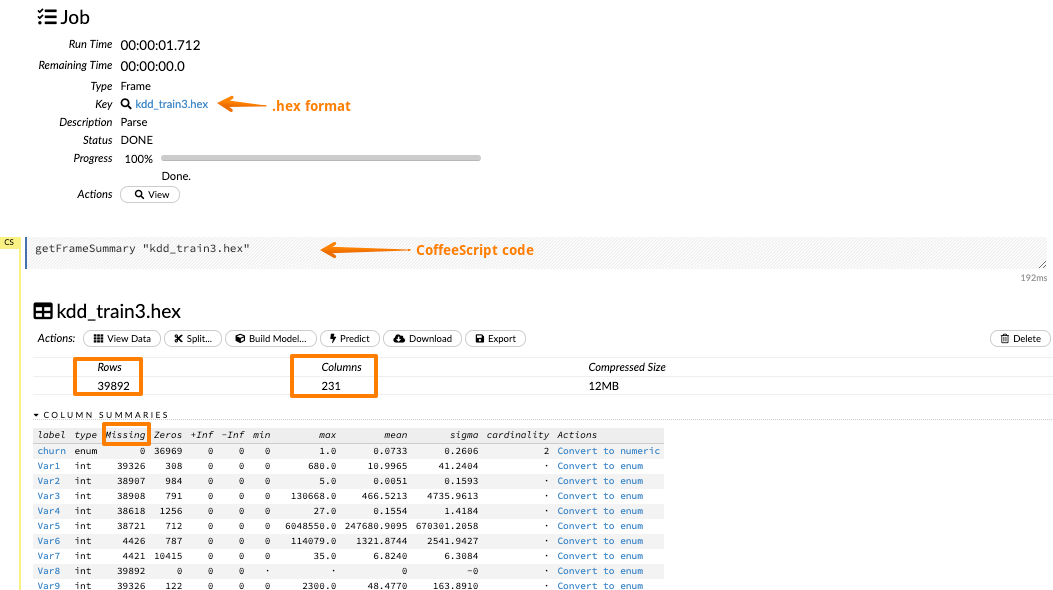
It is also possible to visualize each label data by clicking on the corresponding column. Let’s visualize the churn column and its various distributions.
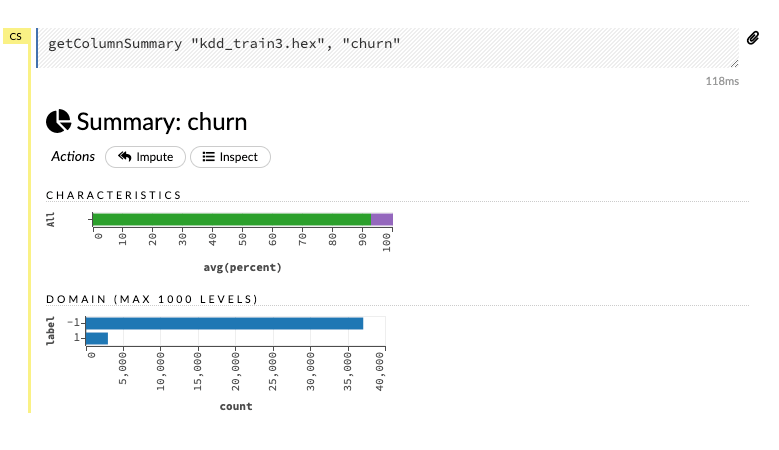
Building Models
Before we proceed with the model building process, two essential things need to be done:
- Imputing the missing data
Click on the Impute option under the Data tab and choose a criterion for imputation on the selected columns of the dataset.
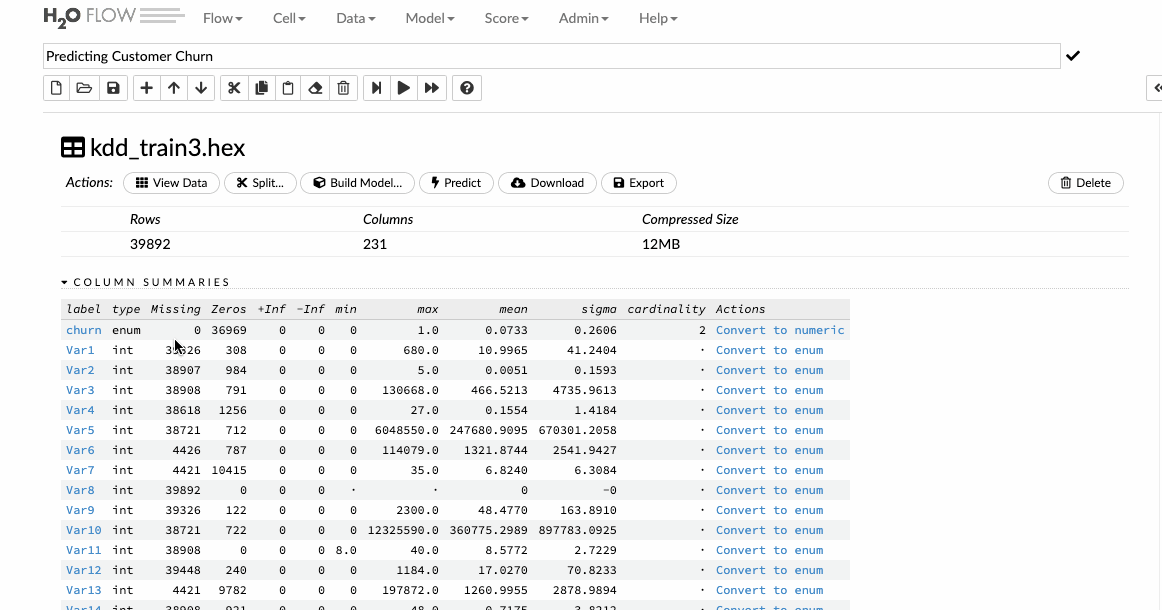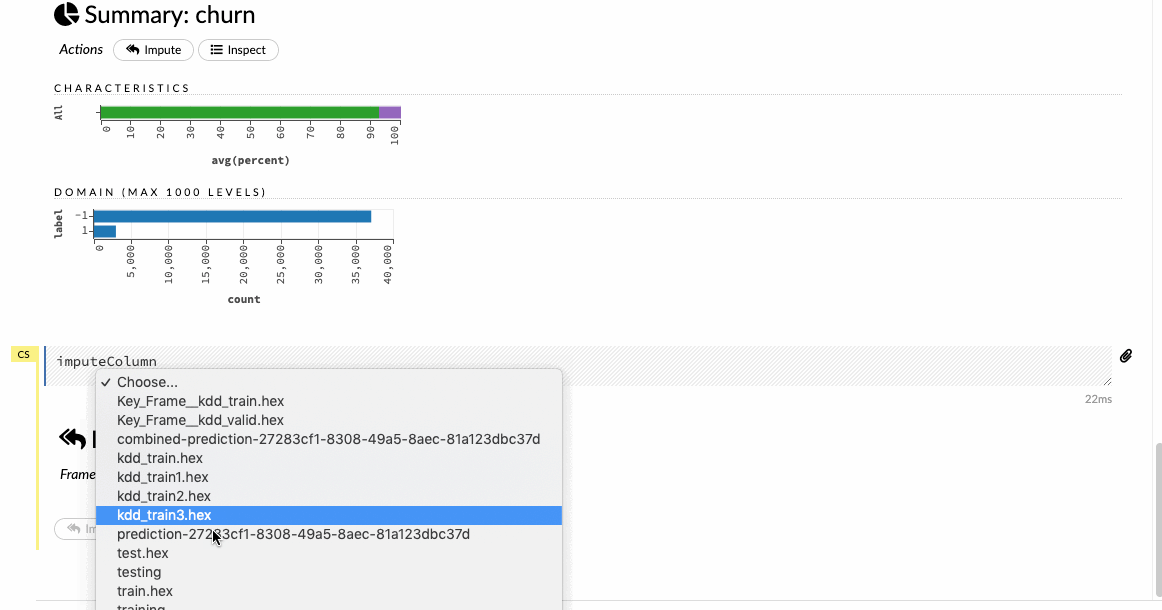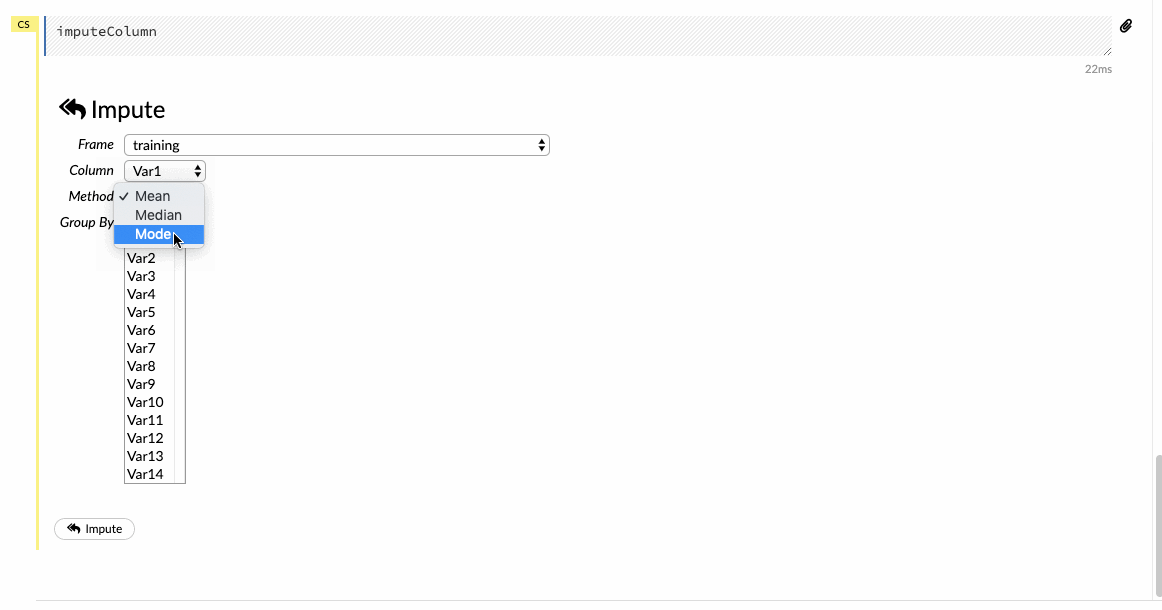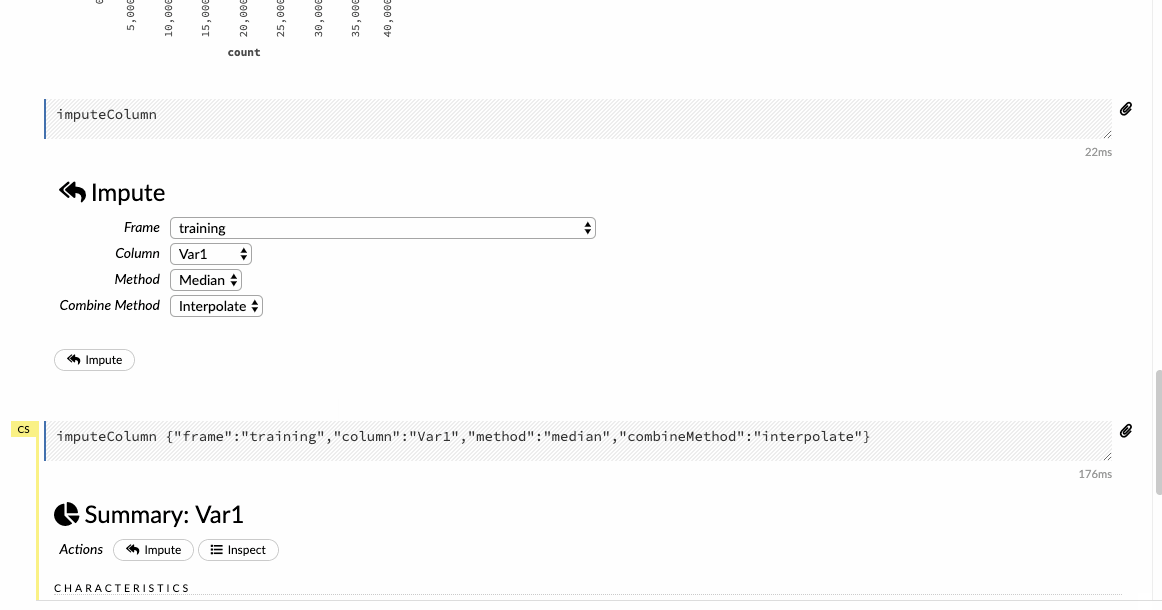
- Splitting data into training and testing set.
Splitting data is achieved by specifying the split ratio and accordingly, a training and a testing frame is created. Click the Data drop-down and select Split Frame.
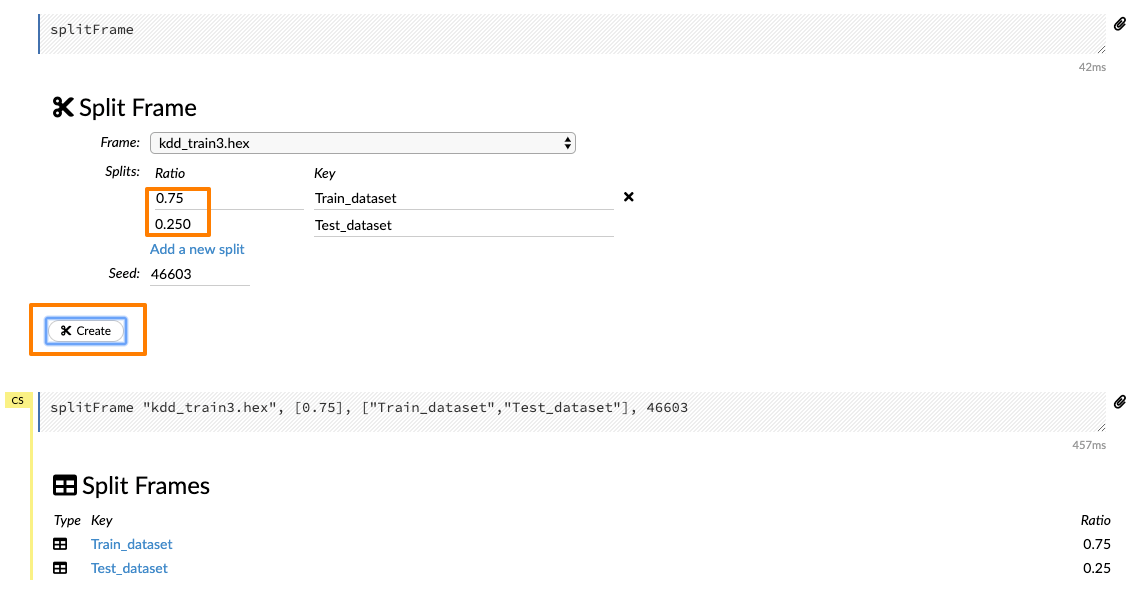
- Building a GBM model
Once you are done with exploring the data, you can start building a predictive model that will be put into production. Click on the Model tab and Flow pulls up a list of all the available algorithms.H2O supports a wide variety of algorithms right from GLM to GBM to AutoML to DeepLearning. Here is the complete list:
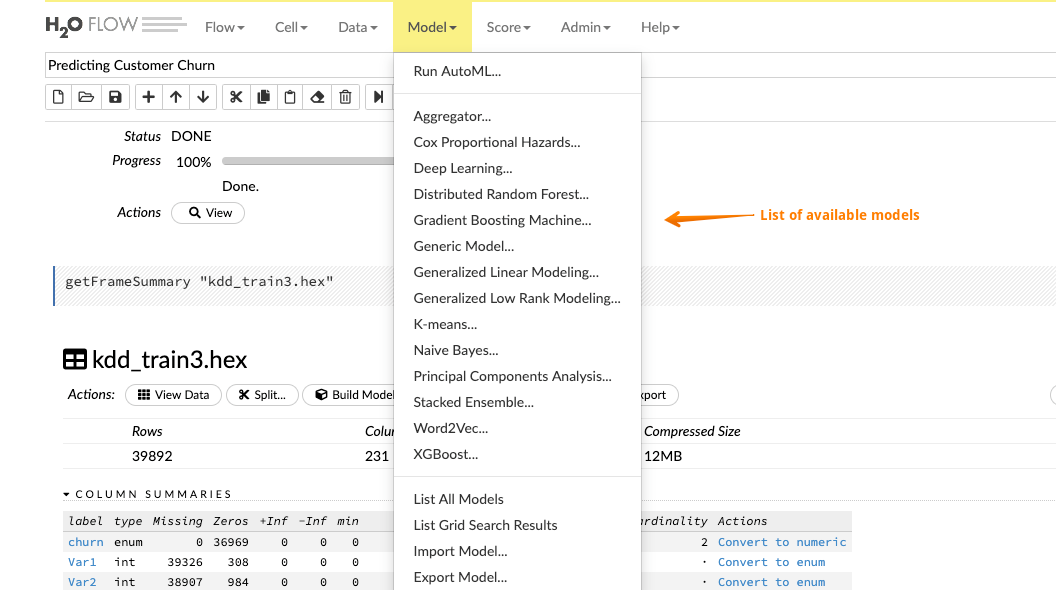
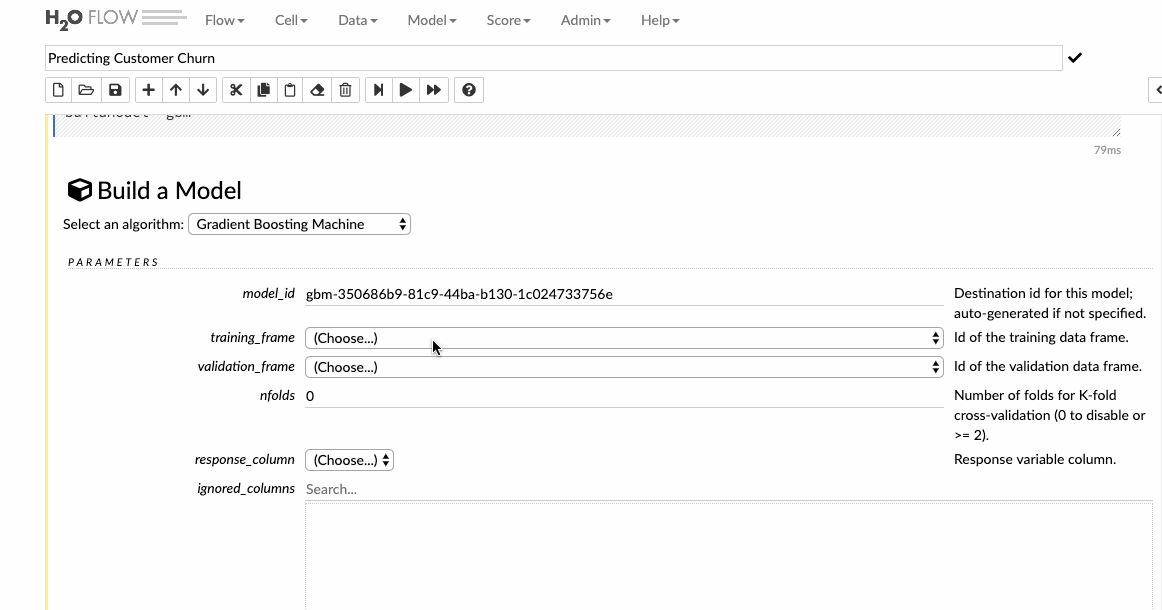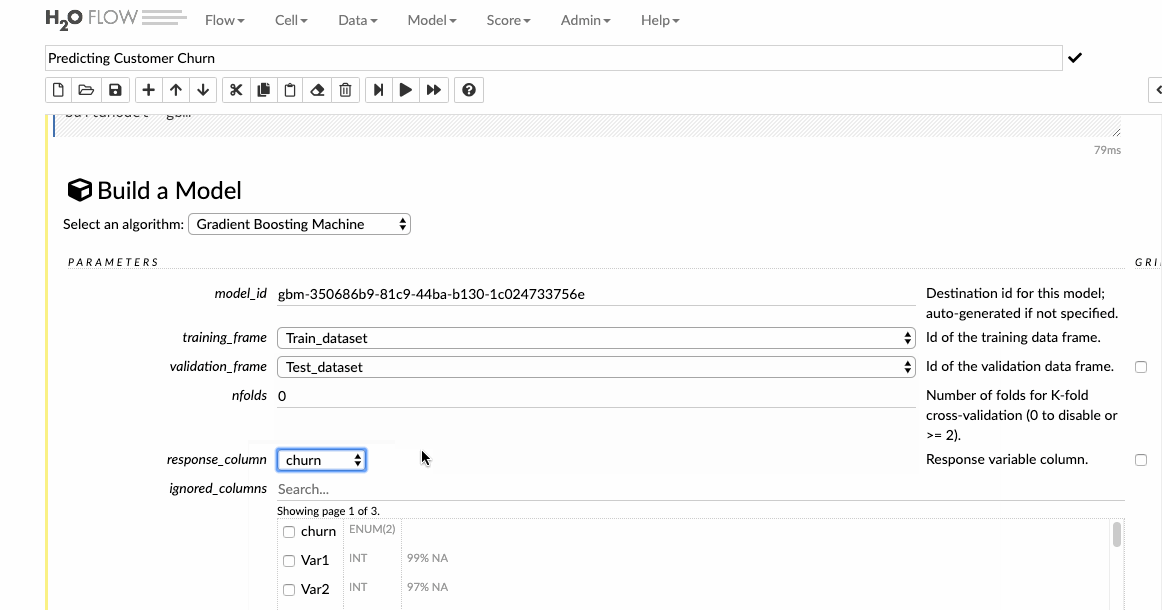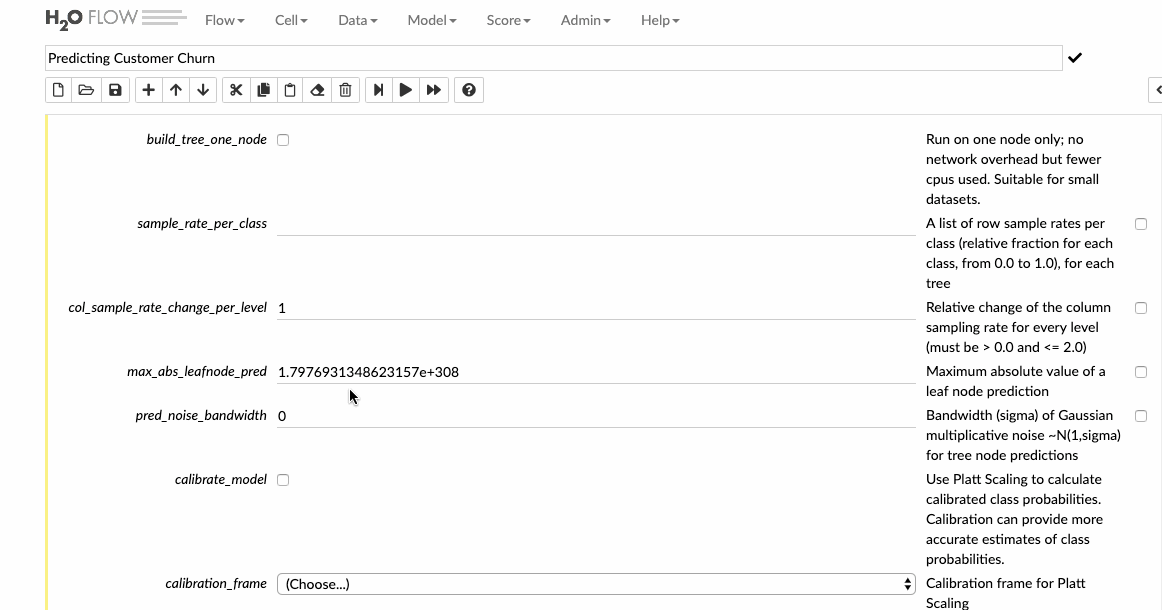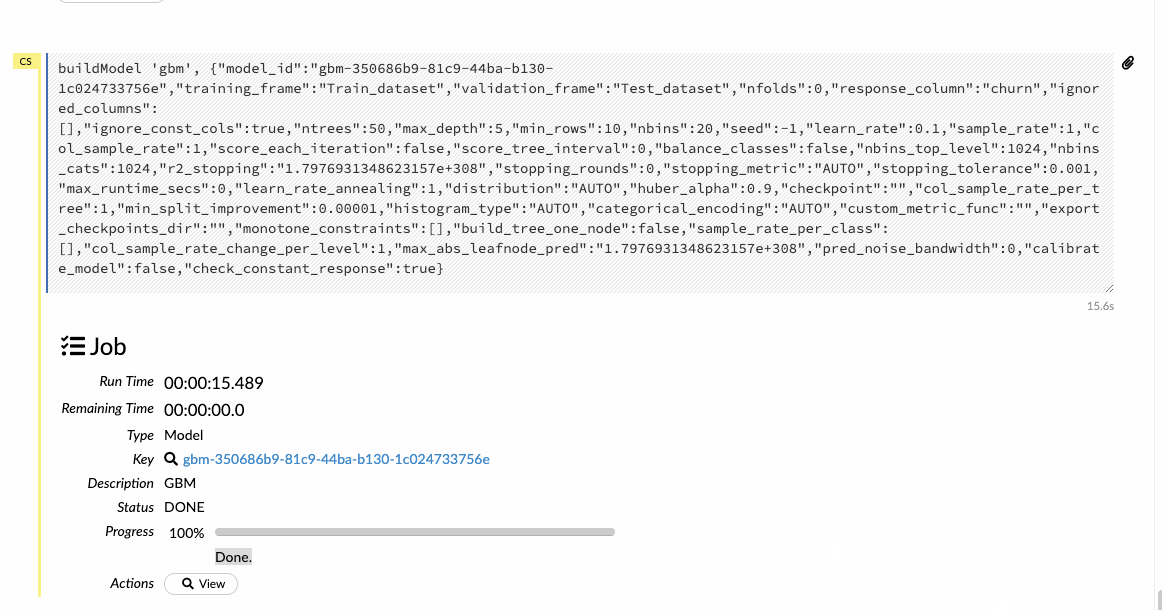
For the sake of this article, we will build a General Boosting machine(GBM), which is a forward learning ensemble method. Choosing the datasets and the response column and leave all the other options as default and then build the model.
Viewing Models
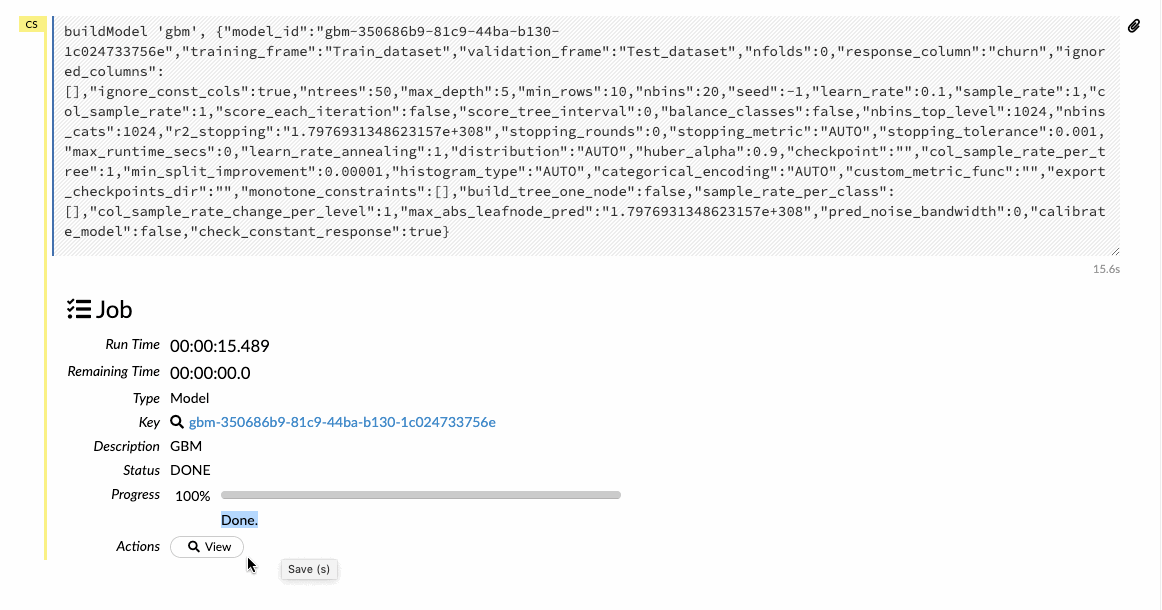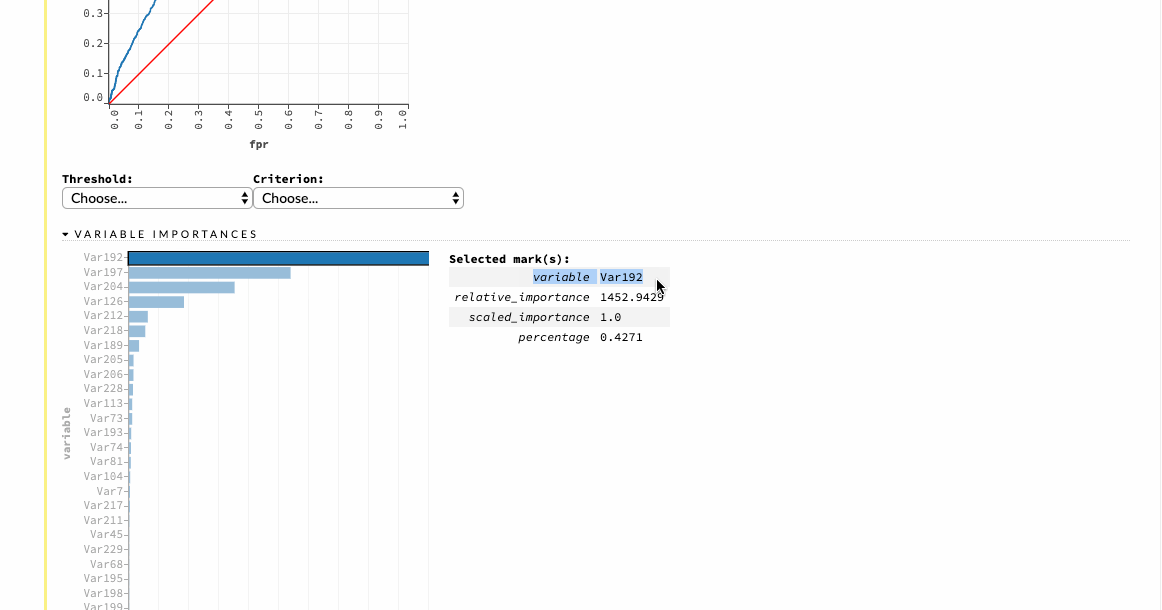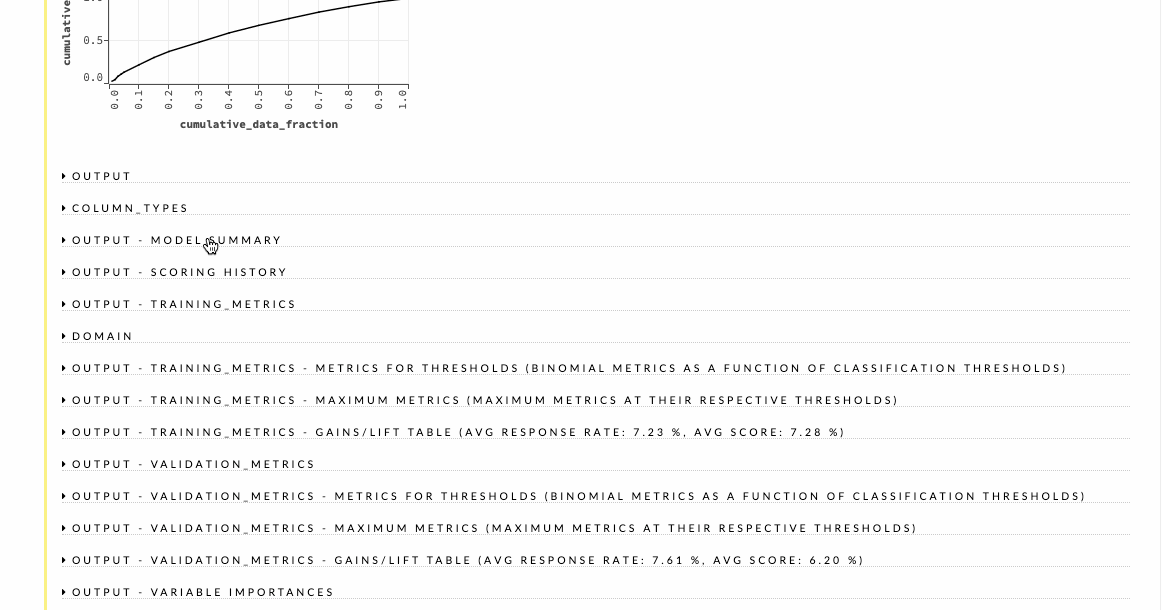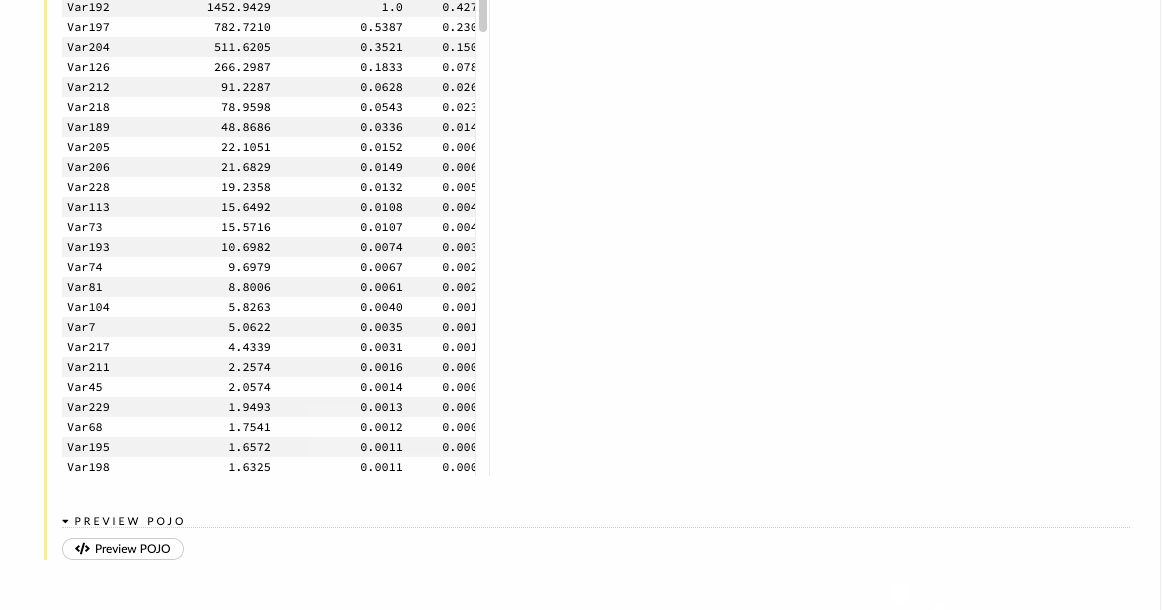
We can also view the model results, which help us to quickly judge how our model has done. We get the scoring history, the ROC curves, variable importance, and a lot of other relevant information which can be very helpful to adjudge the performance of our model.
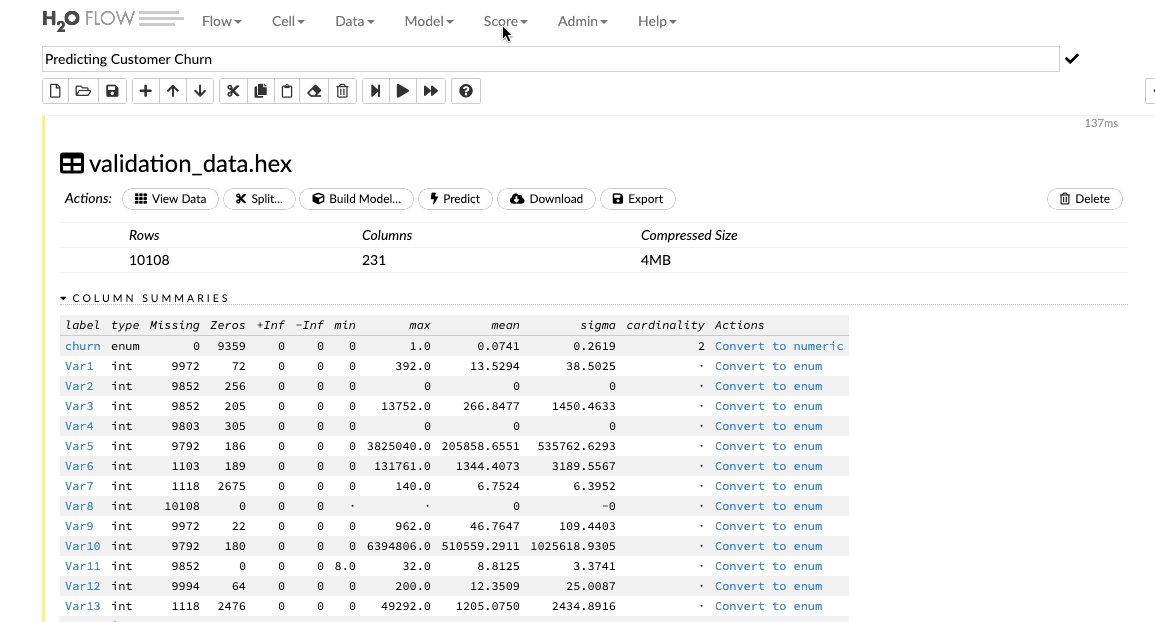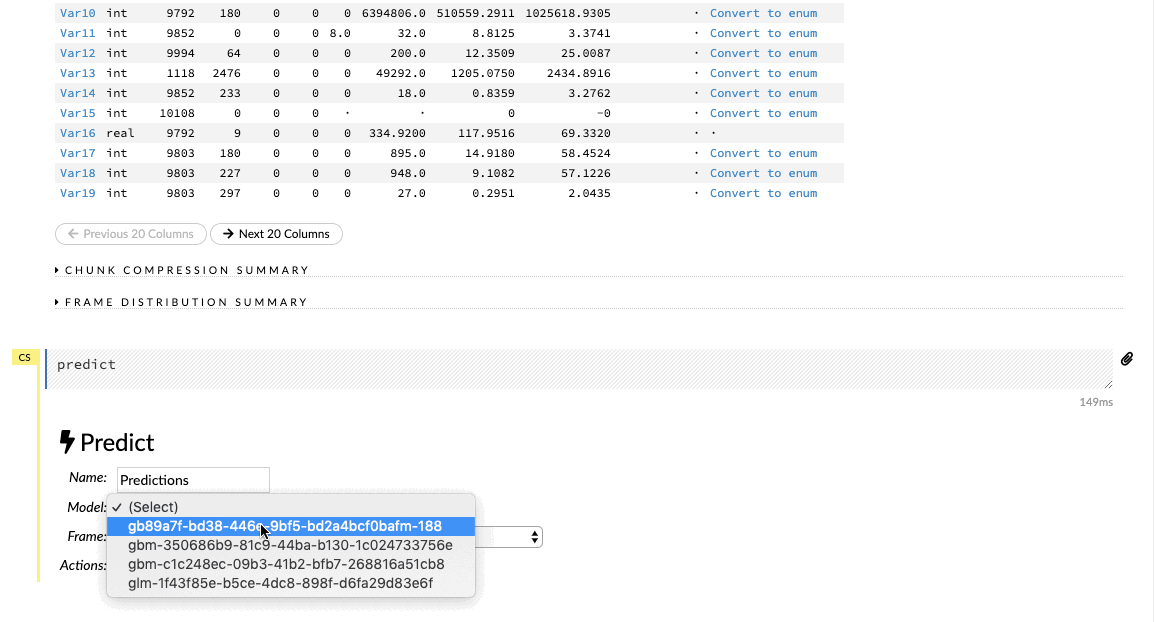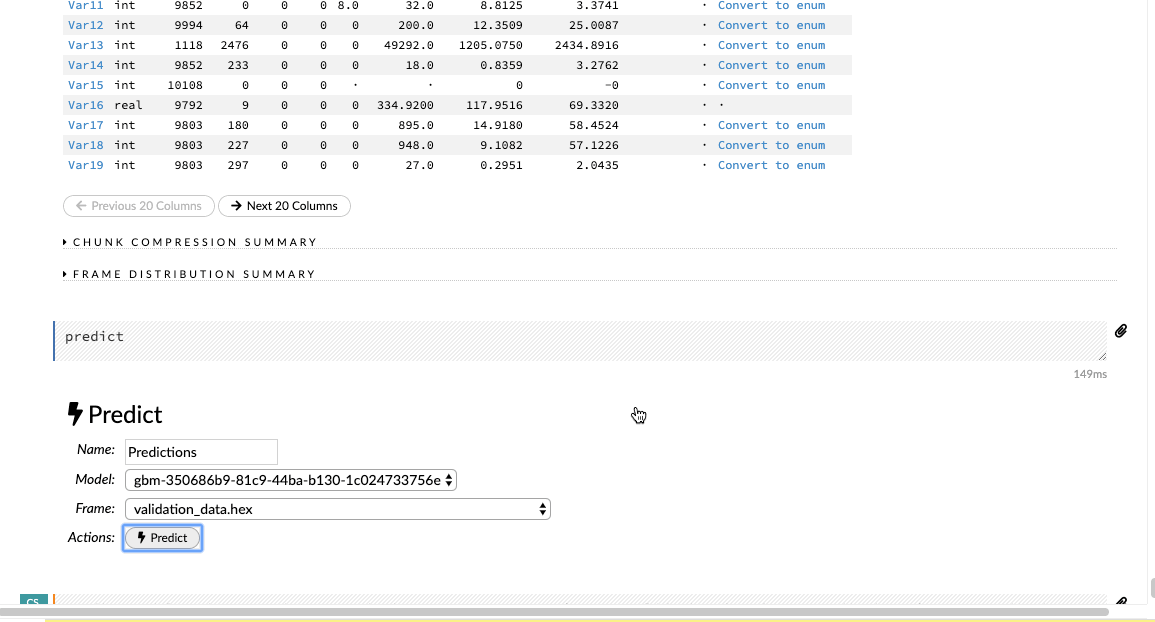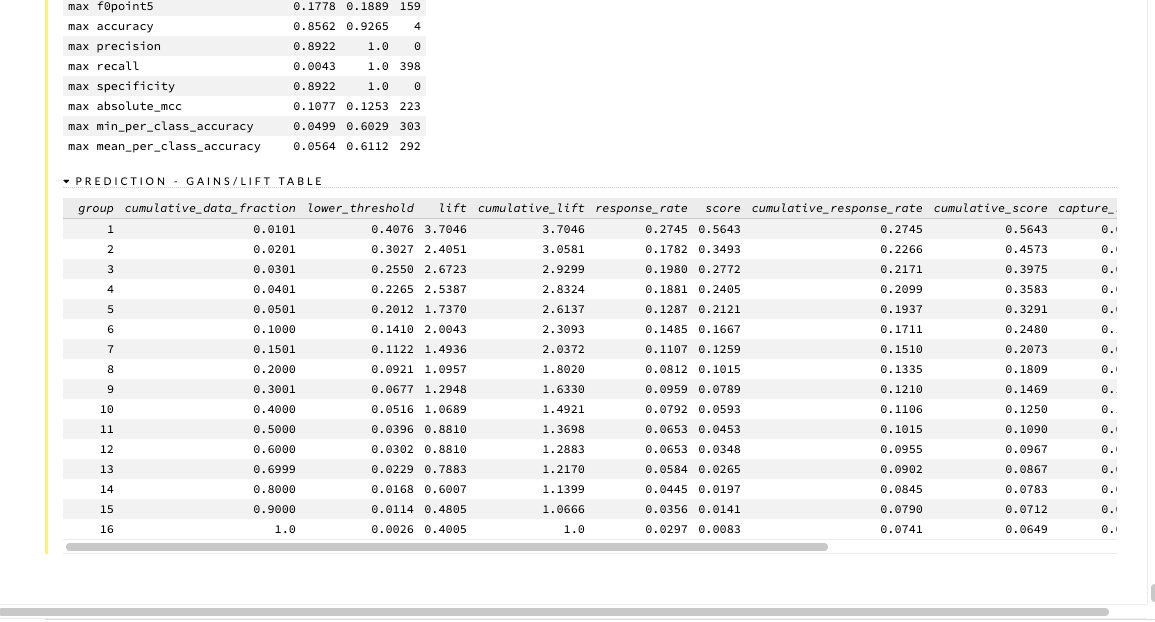
Predictions on Validation Data
After we have built and tuned the parameter of our model to get some decent metrics, we can then make predictions for our validation dataset. Import the validation dataset into the flow interface and click on the Score>Predict tab to make the necessary predictions.
Productionizing Models
The ultimate aim of a data scientist is not only to build a robust model but also a model that can be put into production easily .H2O allows you to convert the models you have built to either a Plain Old Java Object (POJO) or a Model ObJect, Optimized (MOJO). H2O-generated MOJO and POJO models are intended to be easily embeddable in any Java environment. So if there is an internal application for monitoring customer churn, we can easily and quickly export a Plain Old Java Object(POJO) and further pass it on to the developers to integrate it into their existing applications. In this way, our predictive model can become a part of our business process.
Conclusion
The uniqueness of Flow lies in the fact that one can point and click through an entire workflow. However, this point and click mechanism also generates a CoffeeScript which can be edited and modified and can be saved as a notebook to be shared. Thus, all along, we do not blindly click and run, but we are aware of the code behind every executed cell.