


H2O-3 on FfDL: Bringing deep learning and machine learning closer together

This post originally appeared in the IBM Developer blog here.
This post is co-authored by Animesh Singh, Nicholas Png, Tommy Li, and Vinod Iyengar.
Deep learning frameworks like TensorFlow, PyTorch, Caffe, MXNet, and Chainer have reduced the effort and skills needed to train and use deep learning models. But for AI developers and data scientists, it’s still a challenge to set up and use these frameworks in a consistent manner for distributed model training and serving.
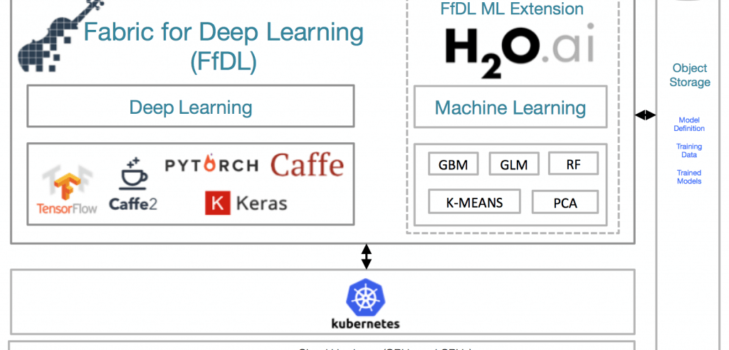
The open source Fabric for Deep Learning (FfDL) project provides a consistent way for AI developers and data scientists to use deep learning as a service on Kubernetes and to use Jupyter notebooks to execute distributed deep learning training for models written with these multiple frameworks.
Now, FfDL is announcing a new addition that brings together that deep learning training capability with state-of-the-art machine learning methods.
Augment deep learning with best-of-breed machine learning capabilities
For anyone who wants to try machine learning algorithms with FfDL, we are excited to introduce H2O.ai as the newest member of the FfDL stack. H2O-3 is H2O.ai’s open source platform, an in-memory, distributed, and scalable machine learning and predictive analytics platform that enables you to build machine learning models on big data. H2O-3 offers an expansive library of algorithms, such as Distributed Random Forests , XGBoost, and Stacked Ensembles, as well as AutoML, a powerful tool for users with less experience in data science and machine learning.
After data cleansing, or “munging,” one of the most fundamental parts of training a powerful and predictive model is properly tuning the model. For example, deep neural networks are notoriously difficult for a non-expert to tune properly. This is where AutoML becomes an extremely valuable tool. It provides an intuitive interface that automates the process of training a large number of candidate models and selecting the highest performing model based on the user’s preferred scoring method.

In combination with FfDL, H2O-3 makes data science highly accessible to users of all levels of experience. You can simply deploy FfDL to your Kubernetes cluster and submit a training job to FfDL. Behind the scenes, FfDL sets up the H2O-3 environment, runs your training job, and streams the training logs for you to monitor and debug your model. Since FfDL also supports multi-node clusters with H2O-3, you can horizontally scale your H2O-3 training job seamlessly on all your Kubernetes nodes. When model training is complete, you can save your model locally to FfDL or to a cloud object store, where it can be obtained later for serving inference.
Try H2O on FfDL today!
You can find the details on how to train H2O models on FfDL in the open source FfDL readme file and guide . Deploy, use, and extend them with any of the capabilities that you find helpful. We’re waiting for your feedback and pull requests!