




Note: I’m grateful to Dr. Erin LeDell for the suggestions, corrections with the writeup. All of the images used here are from the talks’ slides.
Erin Ledell’s talk was aimed at AutoML : Automated Machine Learning , broadly speaking, followed by an overview of H2O’s Open Source Project and the library.
H2O AutoML provides an easy-to-use interface that automates data pre-processing, training and tuning a large selection of candidate models (including multiple stacked ensemble models for superior model performance). The result of the AutoML run is a “leaderboard” of H2O models which can be easily exported for use in production.
The library can be interfaced with R, Python, Scala and even using a Web GUI. The talk also briefly covers R and Python code examples for getting started.
Goals and Features of AutoML
AutoML has been an active area of research for a long time and recently it has seen developments in the Enterprise level. Goals of AutoML:
 Train the best model in the least amount of time.
Train the best model in the least amount of time.
Time here refers to time spent by the user or the expert or the time spent on writing code. Essentially, we’re aiming at saving human hours. Reduce Human Efforts & Expertise in required in ML:
Reduce Human Efforts & Expertise in required in ML:
Efforts are reduced by reducing the manual code-writing time along with reducing the time spent on writing code. The entry-level can be reduced by creating an AutoML having performance ≥Average Data Scientist. Improve the performance of Machine Learning models.
Improve the performance of Machine Learning models. Increase reproducibility and establish a baseline for scientific research or applications: Running an AutoML experiment can provide us a good baseline for our experiments that we can build upon while making sure that the same is reproducible.
Increase reproducibility and establish a baseline for scientific research or applications: Running an AutoML experiment can provide us a good baseline for our experiments that we can build upon while making sure that the same is reproducible.
AutoML/ML Pipeline
The three essential steps of an AutoML Pipeline can be represented as:

The different parts of the respective aspects could be as follows. Note the ones currently supported by H2O AutoML are in bold, though most of the remaining items are in progress or on the roadmap.
Data Preparation :
Feature Engineering and Data Cleaning often come under this aspect.
-
- Imputation, One Hot Encoding, Standardization
Feature Selection /Feature Extraction (PCA)
- Count/Label/Target Encoding of Categorical Features.
Model Generation :
We’d usually be required to train a large number of models to pick 1 Good Model.
- Cartesian Grid Search or Random Grid Search
- Bayesian Hyperparameter Optimization
- Individual models can be tuned using a validation set
Ensembles
Even though this step is optional, it’s often useful when best models are needed. Ensembles often outperform individual models:
- Stacking/Super Learning (Wolpert, Breiman)
- Ensemble Selection (Caruana)
Approaches for ensembling:
- Random Grid Search + Stacked Ensembles is a powerful combination.
- Ensembles perform particularly well if the underlying models are 1. Individually Strong, 2. Make UnCorrelated Errors
- Stacking uses a second-level meta-learning algorithm to find the optimal combination of base learners.
Flavors of AutoML:
There could different categories for tackling Tabular, Time Series, Image Data.
One can also take a neural architecture search, this would, however, be limited to Deep Learning approaches.
Erin talks about these flavors in-depth in this article .
H2O AutoML
You can check out the library here
The following are part of the H2O AutoML Pipeline:
- Basic data pre-processing (as in all H2O algos).
- Trains a random grid of GBMs, DNNs, GLMs, etc. using a carefully chosen hyper-parameter space. The team has spent a lot of time thinking about the algorithms to be used, along with how much time and parameters to be used along with it. This is a kind of-if you may-” Smart Brute-Force”, avoiding the common mistakes.
- Individual models are tuned using cross-validation, to avoid overfitting.
- Two Stacked Ensembles are trained:
– “All Models”: Usually the best performing ensemble-contains an ensemble of all of the models trained.
– “Best of Family”: Best of Each Group (e.g. best GBM, best XGBoost, best RF, etc), usually lighter weight than an all model approach, consider a case where you might have 1000 models: you’d like a better export for production rising. - All models are easily exportable for productionizing.
H2O AutoML: Web GUI
The Web GUI allows simple click and selection for all of the parameters inside of H2O-3.
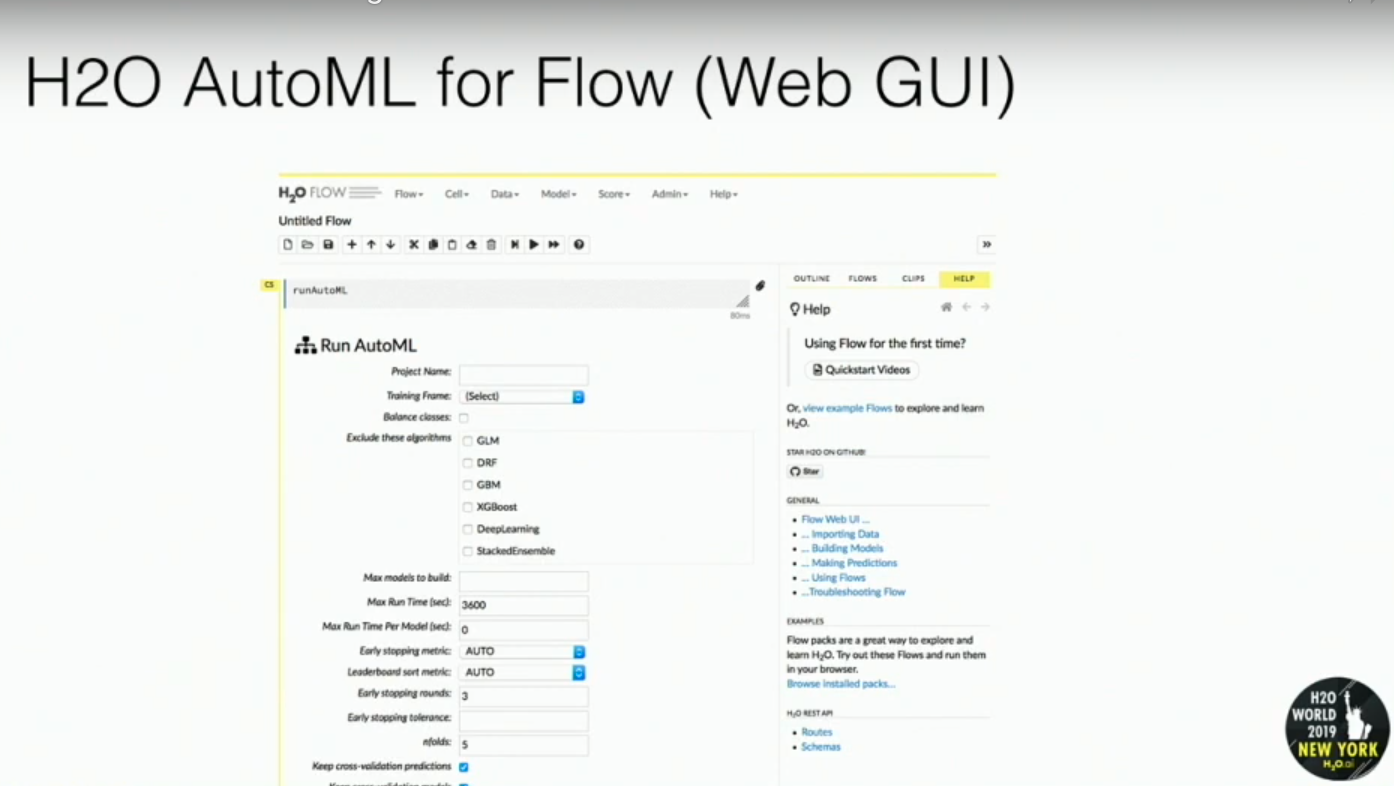
Note: This is spun up by default, whenever you start an H2O cluster on a machine.
R-Interface

Python
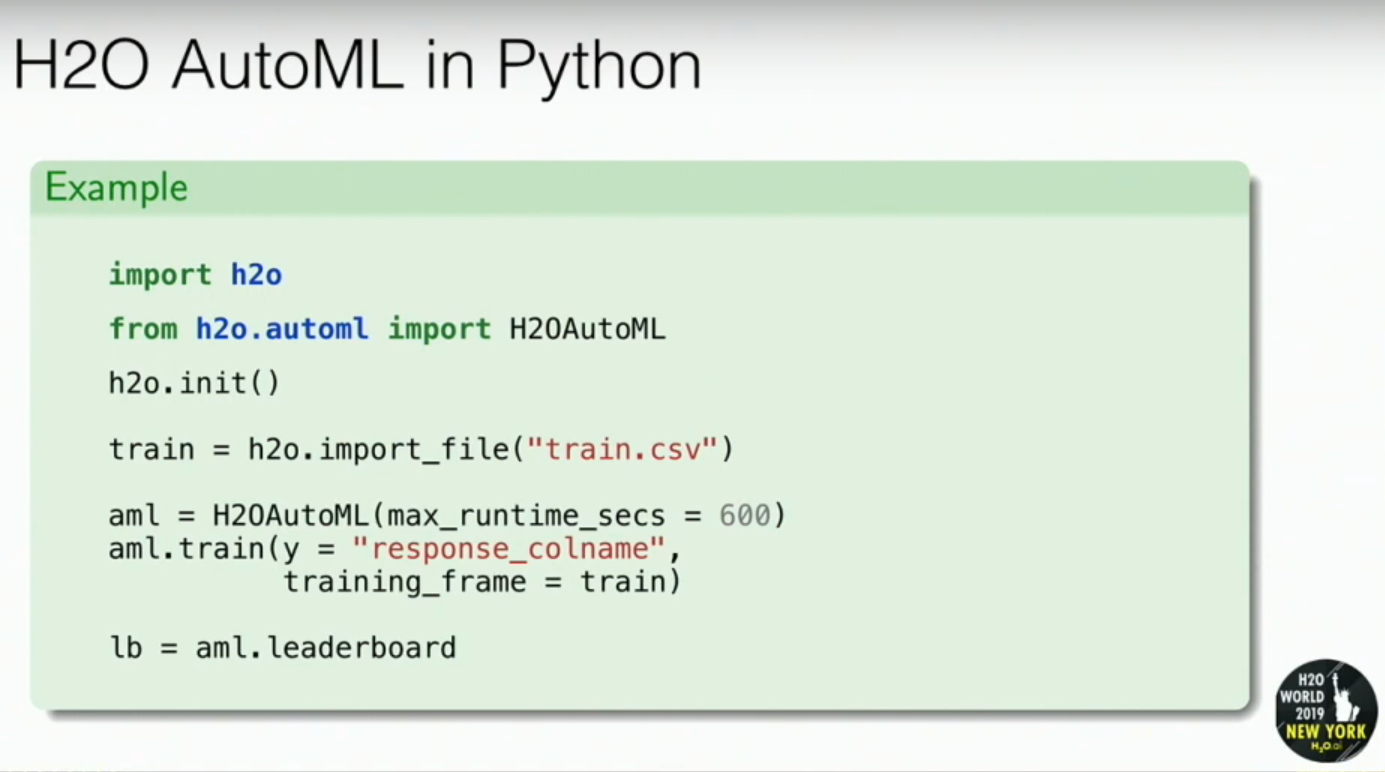
As you can see, the configurations required in a single line of code are:
- Import Data
- Set max_runtime
- Set the target column and point H2OAutoML to the data
- Get the Leaderboard
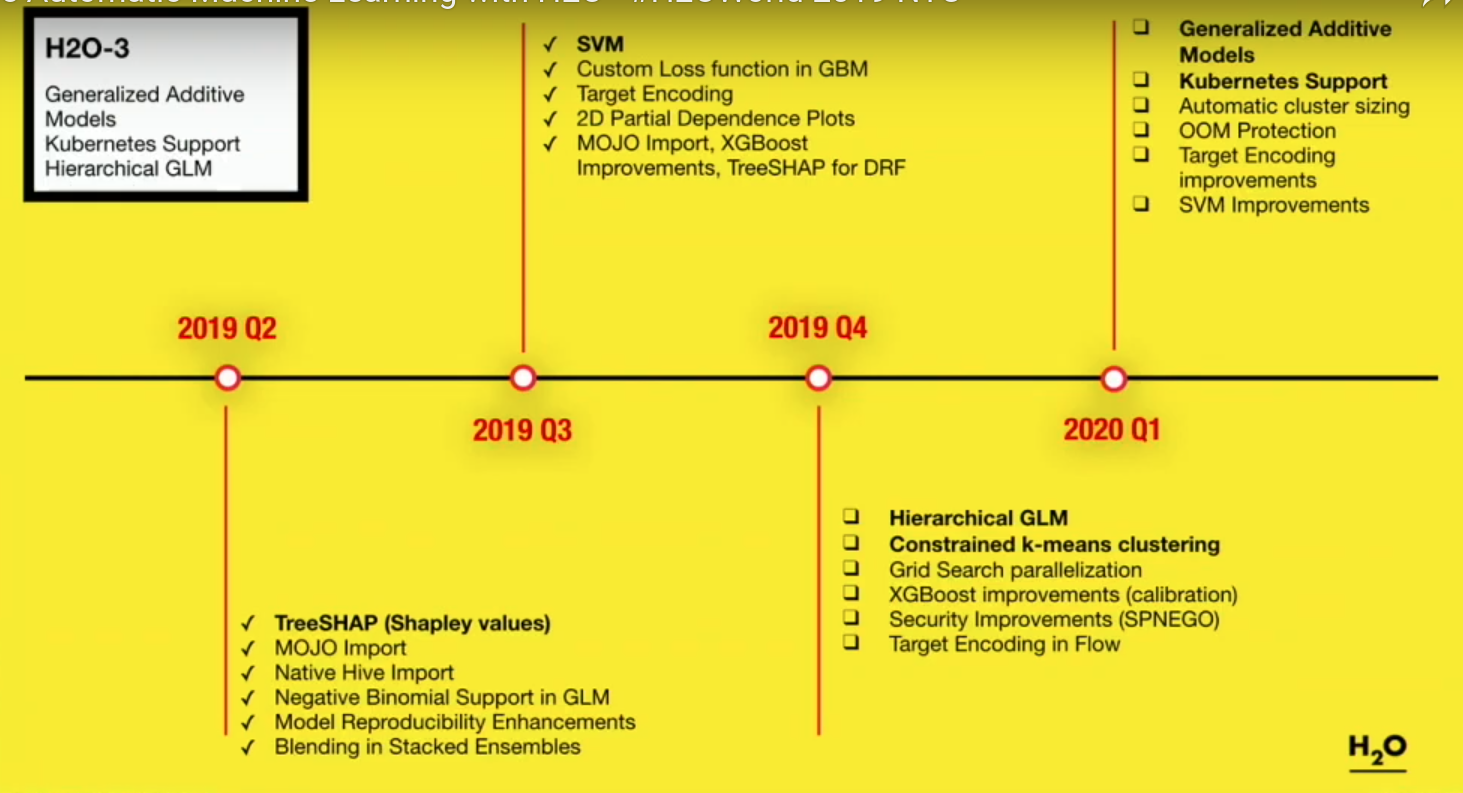
H2O AutoML RoadMap
The AutoML roadmap:
- Automatic target encoding of high cardinality categorical cols
- Better support for wide datasets via feature selection/extraction
- Support text input directly via Word2Vec
- Variable importance for Stacked Ensembles
- Improvements to the models we train based on benchmarking
- Fully customizable model list (grid space, etc)
- New algorithms: SVM, GAM
The roadmap for H2O-3:
Benchmarks
- The team worked with fellow AutoML researchers and OpenML.org, a system for high-quality benchmarks of all the popular open-source AutoML systems.
- You can check out the paper here, it’s been recently accepted at the ICML 2019 AutoML Workshop.
- Github Repo
- Results Visualisations
- Kaggle Reading Group video review of the paper
H2O Community Highlights/Recognition:

Learning Resources:
You can watch the video of Dr. Ledell’s talk here.
