






- Activation Function
- Confusion Matrix
- Convolutional Neural Networks
- Forward Propagation
- Generative Adversarial Network
- Gradient Descent
- Linear Regression
- Logistic Regression
- Machine Learning Algorithms
- Multilayer Perceptron
- Naive Bayes
- Neural Networking and Deep Learning
- RuleFit
- Stack Ensemble
- Word2Vec
- XGBoost
- Automated Machine Learning
- Grid Search
- Hyperparameter Optimization
- Machine Learning
- Machine Learning Lifecycle
- Machine Learning Models
- Multiclass Classification
- Overfitting in Machine Learning | H2O.ai Wiki
- Python AutoML
- Regularization Parameter Lambda
- Supervised Machine Learning
- Support vector machine
- Training Sets
- Unsupervised Machine Learning
- Vector
What is overfitting?
Overfitting occurs when a machine learning model matches the training data too closely, losing its ability to classify and predict new data. An overfit model finds many patterns, even if they are disconnected or irrelevant. The model continues to look for those patterns when new data is applied, however unrelated to the dataset. This causes the model to closely match the training data, but becomes useless for new datasets.
Overfitting vs Underfitting
Overfitting happens when a model has memorized patterns in the training data and fails to adapt to unseen data. Overfit models have high variance and low bias in their shown results.
Underfitting occurs when a learning model oversimplifies the data within it. This is frequently caused by insufficient model training time, or if the data is not complex enough to signify a meaningful relationship. Underfit models show low variance and high bias in their results.
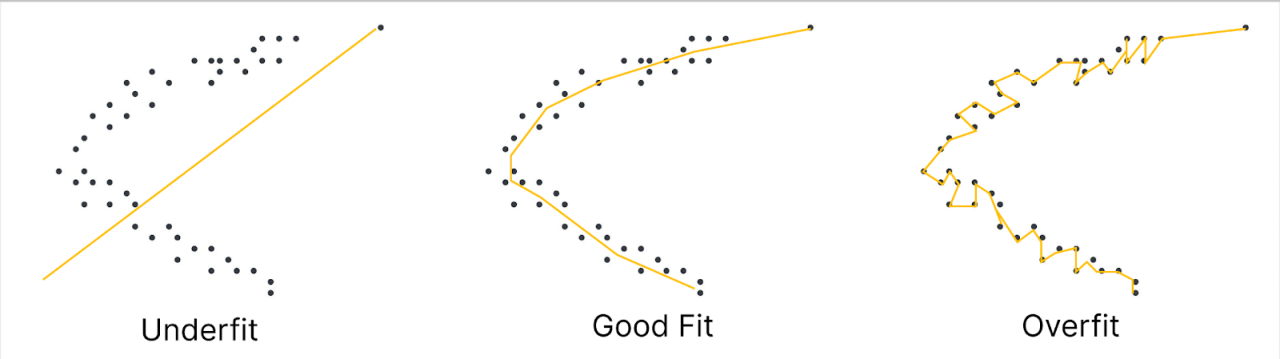
How to detect overfit models
K-fold cross-validation is a common method to check if a learning model is overfit. The k-fold cross-validation process includes:
1. Splitting data into equally sized k “folds” or subsets
2. Choosing a subset to be held aside as the test set
3. Using the remaining subsets to train the model
4. Evaluating and retaining the performance
5. Repeating the process until all subsets have been used as a test set
6. Finding the mean of all subset performances
The averaged score will evaluate the performance of the model.
A simplified version of this cross-validation uses 80% of a set of data to train the learning model. The remaining 20% of that same set is used to test the accuracy of the learning model. The performance of the learning model can be measured by monitoring the percentage of accuracy in the dataset. If the training set of data performs higher than the test set it can be concluded the model is overfit.
How to prevent overfitting
Overfitting can occur when a model is overtrained on a dataset, when there is too much variance or complexity within that dataset, or if the data is unclean. Below are some methods to prevent overfitting in learning models.
Early Stopping
One common way to prevent a learning model from becoming overfit is to pause the training. This prevents the model from becoming hypersensitive to small patterns or noise in the data. As mentioned earlier, underfitting occurs when a model has stopped training too early, making it important to train within the recommended time.
Adding More Data
Increasing the dataset in the learning model can increase the accuracy by providing more data to sort through. Additional data in the model will provide opportunities for dissecting a meaningful relationship with the dataset. This method is only effective when adding relevant and clean data. Adding irrelevant or dirty data can cause the model to become overly complex, resulting in overfitting.
Data Augmentation
This approach is interchangeable with the previous method. Data augmentation allows the test data to appear slightly different from the learning model each time a dataset is processed. This prevents the model from overlearning the dataset. Data augmentation can, at times, be preferable to adding more data as it does not require continual data collection.
Ensemble Methods
The two main ensemble methods are boosting and bagging.
The boosting method uses simple base models and increases their complexity. The model is trained by a large number of weak learners in a sequence, enabling each learner to improve upon the weaknesses of learners in the previous sequence. The boosting method combines multiple weak learners to create one strong learner.
The bagging method uses random data samples in a training set and selects samples with replacements. Several weak learners are generated and the model independently trains those datasets in parallel. The average of those predictions generally forecasts more accurate results. This method is commonly used to reduce variance within a noisy set of data.
Regularization methods
Regularization methods such as L1, LASSO, and dropout can be applied to a dataset to calibrate the model, which can reduce variance, noise, and prevent overfitting.
Read more on different regularization methods
Tuning a GBM
H2O.ai enables `min_split_improvement` which can prevent a model from overfitting noise.
Read more about tuning a GMB on H2O 3
H2O.ai + overfitting
H2O Driverless AI offers ways to prevent overfitting in machine learning models. Our product offers early stopping, ensuring every model stops when it cannot continue to improve holdout data. Driverless AI also calculates the mean out-of-fold data through cross validation on certain models.
For more information on how Driverless AI can prevent overfitting, click here or read the resources below:
Overfitting Resources
https://docs.h2o.ai/h2o/latest-stable/h2o-docs/data-science/algo-params/alpha.html
https://docs.h2o.ai/h2o/latest-stable/h2o-docs/data-science/gbm-faq/tuning_a_gbm.html
https://docs.h2o.ai/h2o/latest-stable/h2o-docs/data-science/glm.html#regularization
https://docs.h2o.ai/driverless-ai/latest-stable/docs/userguide/faq.html#overfitting-prevention